搜索到
106
篇与
的结果
-
 ElasticSearch 分享 ES的基本概念ES的介绍Elasticsearch 是一个分布式、Restful风格、基于 Apache Lucene 的分布式搜索引擎,由elastic公司开发并基于Apache许可条款发布源码。其核心功能可以用两个词来概括:搜索(search)和分析(analysis)。Elasticsearch 为所有的数据类型提供了近乎实时的搜索和分析功能。无论数据类型是结构化文本还是非结构化文本,数字类型或者地理数据类型等,Elasticsearch 都能高效的进行存储,并且以一定的方式构建索引来实现快速搜索。而且因为其天生的分布式特性,数据量增大的同时,部署也可以无缝升级。Elasticsearch索引的精髓:一切设计都是为了提高搜索的性能。2013年初,GitHub抛弃了Solr,采取ElasticSearch 来做PB级的搜索。 GitHub使用ElasticSearch搜索20TB的数据,包括13亿文件和1300亿行代码维基百科:启动以elasticsearch为基础的核心搜索架构SoundCloud:SoundCloud使用ElasticSearch为1.8亿用户提供即时而精准的音乐搜索服务百度:百度目前广泛使用ElasticSearch作为文本数据分析,采集百度所有服务器上的各类指标数据及用户自定义数据,通过对各种数据进行多维分析展示,辅助定位分析实例异常或业务层面异常。目前覆盖百度内部20多个业务线(包括casio、云分析、网盟、预测、文库、直达号、钱包、风控等),单集群最大100台机器,200个ES节点,每天导入30TB+数据新浪使用ES 分析处理32亿条实时日志阿里使用ES 构建挖财自己的日志采集和分析体系ES和lucene的区别Lucene只支持Java,ES支持多种语言。Lucene非分布式,ES支持分布式。Lucene非分布式的,索引目录只能在项目本地 , ES的索引库可以跨多个服务分片存储。Lucene使用非常复杂,ES屏蔽了Lucene的使用细节,操作更方便。单体/小项目使用Lucene ,大项目或分布式项目使用ES。ES的竞品分析Solr:Solr 利用 Zookeeper(注册中心) 进行分布式管理,支持更多格式的数据(HTML/PDF/CSV),官方提供的功能更多在传统的搜索应用中表现好于 ES,但实时搜索效率低。ES自身带有分布式协调管理功能,但仅支持json文件格式,本身更注重于核心功能,高级功能多有第三方插件提供,在处理实时搜索应用时效率明显高于 Solr。Solr 利用 Zookeeper 进行分布式管理,而 Elasticsearch 自身带有分布式协调管理功能;Solr 支持更多格式的数据,而 Elasticsearch 仅支持json文件格式;Solr 官方提供的功能更多,而 Elasticsearch 本身更注重于核心功能,高级功能多有第三方插件提供;Solr 在传统的搜索应用中表现好于 Elasticsearch,但在处理实时搜索应用时效率明显低于 ElasticsearchKatta:基于 Lucene 的,支持分布式,可扩展,具有容错功能,准实时的搜索方案。优点:开箱即用,可以与 Hadoop (大数据)配合实现分布式。具备扩展和容错机制。缺点:只是搜索方案,建索引部分还是需要自己实现。在搜索功能上,只实现了最基本的需求。成功案例较少,项目的成熟度稍微差一些。HadoopContrib:Map/Reduce 模式(云计算)的,分布式建索引方案,可以跟 Katta 配合使用。优点:分布式建索引,具备可扩展性。缺点:只是建索引方案,不包括搜索实现。工作在批处理模式,对实时搜索的支持不佳。ES的特点高容量:集群支持PB级数据的存储和查询。高吞吐:支持对海量数据近实时的数据处理。高可用:基于副本机制支持部分服务宕机后仍可正常运行和使用。支持多维度数据分析和处理:除了支持全文检索, 还支持基于单字段精确查询和多字段联合查询等复杂的数据查询操作。API 简单易用: API 简单易用,除了支持 RestfulApi,还支持 Java、Python 等多客户端形式,且查方式简单灵活。支持插件机制: 支持插件式开发,基于 ElasticSearch 可以开发自己的分词插件、同步插件、 Hadoop 捅件 可视化插件。ES的应用场景全文检索:底层基于 Lucene 实现 ,十分适合类 百度百科、维基百科等全文检索的应用场景分布式数据库: 可作为分布式数据库,为大数据云计算提供数据存储和查询服务,广泛应用于淘宝、 京东等电商平台的商品管理和检索服务日志分析:通 logstash 日志采集组件,可实现复杂的日志数据存储分析和查询,最常用的组合是 ELK ( ElasticSearch、Logstash、Kibana )技术组合运维监控:运维平台可以 ElasticSearch 实现大规模服务的监控和管理BI系统:广泛应用于 ( Business Intelligence ,商业智能)系统,例如按照区域统计用户的操作习惯等。Lucene的介绍Lucene架构倒排索引在实际应用中,我们常常需要根据属性的值来查找记录,这时就需要使用倒排索引 ( Inverted Index )。 倒排索引表中的每一项都包括一个属性值和具有该属性值对应记录的地址,由于不是按照记录来确定属性值的,而是由属性值来确定记录的位置的,因此被称为倒排索引。例如,当我们在百度搜索栏中输入关键词时,百度会按照输入的关键词,在所有文档内容(比如网页内容)中搜索与关键词相关的记录(比如网站),并将内容相关的记录的地址(比如网站的地址)返回用户,然后用户便可按该记录的地址进一步查看记录的详细信息。搜索引擎的关键是建立倒排索引,倒排索引一般表示一个关键词,以及它的频度 (出现的次数)和位置(出现在哪一篇文章或网页中,以及相关的日期、作者等信息) 带有倒排索引的文件被称为倒排索引文件( Inverted File ), 倒排索引的索引对象是文档或者文档集合中的单词,倒排索引文件被用来存储这些单词在一个文档或者一组文档中的位置。倒排索引数据结构倒排索引的核心分为两部分:单词词典(Term Dictionary):记录所有文档的单词以及单词到倒排列表的关联关系,实际生产中,单词量会非常大,所以实际会采用 B+ 树和哈希拉链法去存储单词的词典,以满足高性能的插入与查询。倒排列表(Posting List):它记录了单词对应文档的结合,倒排列表是由倒排索引项(Posting) 组成,倒排索引项包含:文档 ID:用于获取原始信息词频(TF,Term Frequency):该单词在文档中出现的次数,用于相关性评分位置(Position):单词在文档中分词的位置,用于语句搜索(Phrase Query)偏移(Offset):记录单词的开始结束位置,实现高亮显示(比如用 GitHub 搜索的时候,搜索的关键词会高亮显示)一个倒排索引是由单词词典(Term Dictionary)和倒排列表(Posting List)组成的,单词词典会记录倒排列表中每个单词的偏移位置。比如当搜索 Allen 的时候,首先会通过单词词典快速定位到 Allen,然后从 Allen 这里拿到在倒排列表中的偏移,快速定位到在倒排列表中的位置,从而真正拿到倒排索引项 [12,15](这里只是列了下 Document ID,其实是像上面讲的包含 4 项信息的项),拿到这个项可以去索引上拿到原始信息,可以去计算打分排序返回给用户。全文检索流程常用术语索引(index):相当于关系型数据库中的数据库,8.x 不再支持type,所以索引也可以看作为数据库中的表。一个索引就是一个拥有几分相似特征的文档的集合。比如说,你可以有一个客户数据的索引,另一个产品目录的索引,还有一个订单数据的索引。一个索引由一个名字来标识(必须全部是小写字母),并且当我们要对这个索引中的文档进行索引、搜索、更新和删除的时候,都要使用到这个名字。在一个集群中,可以定义任意多的索引。能搜索的数据必须索引,这样的好处是可以提高查询速度,比如:新华字典前面的目录就是索引的意思,目录可以提高查询速度。类型(type):相当于传统数据库中的表。这个在 7.x 版本中已经被标注过期,在 8.x 版本中不再支持。7.x 之后默认类型为:_doc。文档(document):相当于关系型数据库中的一行数据。文档以JSON格式来表示,在一个index/type里面,你可以存储任意多的文档。域(field):相当于关系型数据库中的字段,对文档数据根据不同属性进行的分类标识。映射(mapping):相当于传统数据库中的建表语句,可以设置一些列中的数据类型及其他一些特性,如果不设置 mapping,则会默认创建。默认情况下,Elasticsearch中的每个索引被分片5个主分片和1个复制,这意味着,如果你的集群中至少有两个节点,你的索引将会有5个主分片和另外5个复制分片(1个完全拷贝),这样的话每个索引总共就有10个分片。mapping映射mapping是处理数据的方式和规则方面做一些限制,如:某个字段的数据类型、默认值、分析器、是否被索引等等。这些都是映射里面可以设置的,其它就是处理ES里面数据的一些使用规则设置也叫做映射,按着最优规则处理数据对性能提高很大,因此才需要建立映射,并且需要思考如何建立映射才能对性能更好。mapping作用定义索引中的字段的名称定义字段的数据类型,比如字符串、数字、布尔字段,倒排索引的相关配置,比如设置某个字段为不被索引、记录 position 等简单的定义示例{ "mappings": { "_doc": { "dynamic": false }, "properties": { "productId": { //商品ID "type": "long" }, "price": { //商品价格 "type": "keyword" }, "discountPrice": { //商品折扣价格 "type": "keyword" }, "productName": { //商品名称 "type": "text", "analyzer": "ik_smart" //按照ik_smart进行分词 }, "productImg": { //商品图片 "type": "text", "index": false, //不允许被查询 "doc_values": false //不允许被聚合 }, "brandId": { //品牌ID "type": "long" }, "brandName": { //品牌名称 "type": "keyword" }, "oneCategoryId": { //一级分类ID "type": "long" }, "oneCategoryName": { //一级分类名称 "type": "keyword" }, "twoCategoryId": { //二级分类ID "type": "long" }, "twoCategoryName": { //一级分类名称 "type": "keyword" }, "lockCnt": { //热销 "type": "long" }, "publishStatus": { //状态 "type": "long" }, "productEffect": { //功效 "type": "nested", //防止在es库中被扁平处理 "properties": { "productEffectId": { "type": "long" }, "productEffectName": { "type": "keyword" } } }, "skin": { //肤质 "type": "nested", "properties": { "skinId": { "type": "long" }, "skinName": { "type": "keyword" } } } } } }在创建一个索引的时候,可以对 dynamic 进行设置,可以设成 false、true 或者 strict。如果是新增加的字段,根据 Dynamic 的设置分为以下三种状况:当 Dynamic 设置为 true 时,一旦有新增字段的文档写入,Mapping 也同时被更新。当 Dynamic 设置为 false 时,索引的 Mapping 是不会被更新的,新增字段的数据无法被索引,也就是无法被搜索,但是信息会出现在 _source 中。当 Dynamic 设置为 strict 时,文档写入会失败。另外一种是字段已经存在,这种情况下,ES 是不允许修改字段的类型的,因为 ES 是根据 Lucene 实现的倒排索引,一旦生成后就不允许修改,如果希望改变字段类型,必须使用 Reindex API 重建索引。不能修改的原因是如果修改了字段的数据类型,会导致已被索引的无法被搜索,但是如果是增加新的字段,就不会有这样的影响。mapping设置数据类型ES 字段类型主要有:核心类型、复杂类型、地理类型以及特殊类型。注意项:text 类型适用于需要被全文检索的字段,例如新闻正文、邮件内容、商品名称、公告内容等比较长的文字,text 类型会被 Lucene 分词器(Analyzer)处理为一个个词项,并使用 Lucene 倒排索引存储,text 字段不能被用于排序,如果需要使用该类型的字段只需要在定义映射时指定 JSON 中对应字段的 type 为 text。keyword 适合简短、结构化字符串,例如品牌、姓名、生产地、邮箱、ip等通常不需要拆的数据,可以用于过滤、排序、聚合检索,也可以用于精确查询。对象类型JSON 字符串允许嵌套对象,一个文档可以嵌套多个、多层对象。可以通过对象类型来存储二级文档,不过由于 Lucene 并没有内部对象的概念,ES 会将原 JSON 文档扁平化,例如文档{ "name": { "first": "zhang", "last": "yong } }实际上 ES 会将其转换为以下格式,并通过 Lucene 存储,即使 name 是 object 类型:{ "name.first": "zhang", "name.last": "yong" }嵌套类型嵌套类型可以看成是一个特殊的对象类型,可以让对象数组独立检索,例如文档:{ "group": "users", "username": [ { "first": "lv", "last": "wei"}, { "first": "zhang", "last": "san"}, { "first": "li", "last": "si"} ] }username 字段是一个 JSON 数组,并且每个数组对象都是一个 JSON 对象。如果将 username 设置为对象类型,那么 ES 会将其转换为:{ "group": "users", "username.first": ["lv", "zhang", "li"], "username.last": ["wei", "san", "si"] }可以看出转换后的 JSON 文档中 first 和 last 的关联丢失了,如果尝试搜索 first 为 lv,last 为 wei 的文档,那么成功会检索出上述文档,但是 lv 和 wei 在原 JSON 文档中并不属于同一个 JSON 对象,应当是不匹配的,即检索不出任何结果。嵌套类型就是为了解决这种问题的,嵌套类型将数组中的每个 JSON 对象作为独立的隐藏文档来存储,每个嵌套的对象都能够独立地被搜索,所以上述案例中虽然表面上只有 1 个文档,但实际上是存储了 4 个文档。Dynamic MappingDynamic Mapping 机制使我们不需要手动定义 Mapping,ES 会自动根据文档信息来判断字段合适的类型,但是有时候也会推算的不对,比如地理位置信息有可能会判断为 Text,当类型如果设置不对时,会导致一些功能无法正常工作,比如 Range 查询。ES 类型的自动识别是基于 JSON 的格式,如果输入的是 JSON 是字符串且格式为日期格式,ES 会自动设置成 Date 类型;当输入的字符串是数字的时候,ES 默认会当成字符串来处理,可以通过设置来转换成合适的类型;如果输入的是 Text 字段的时候,ES 会自动增加 keyword 子字段,还有一些自动识别如下图所示:ES的集群相关集群的架构master node:整个集群的管理者,索引管理,分片管理,以及整个集群的状态的管理,master节点是从master候选节点中选出的,成为master候选节点的方式: node.master:true 默认(true)data node:数据节点,存储主要数据,负责索引的数据的检索和聚合等操作,成为data node的方式: node.data:true 默认(true)coordinating node:协调节点,所有节点都可以接受来自客户端的请求进行转发,因为每个节点都知道集群的所有索引分片的分布情况,但是别的节点,都还肩负着别的工作,如果请求压力过大,可能会拖垮整个集群的响应速度,所以就专门有了这个协调节点,他什么都不用做,只处理请求和请求结果,所以成为coordinating node的方式: node.data:false node.master:falseingest node:预处理节点,主要是对数据进行预处理,比如对字段重命名,分解字段内容,增加字段等,类似于Logstash, 就是对数据进行预处理,ingest里面可以定义pipeline(管道),pipeline可以由很多个processor(官方预定义28个)构成,用来出来预处理数据,使用方式:先定义好预处理pipeline,然后在存储数据的时候指定pipeline,如:成为ingest node的方式: node.ingest:true 默认(true)脑裂问题产生原因集群维护一个单个索引并有一个分片和一个复制节点。节点1在启动时被选举为主节点并保存主分片(在下面的schema里标记为0P),而节点2保存复制分片(0R)。这时如果在两个节点之间的通讯中断了(网络问题或只是因为其中一个节点无响应(例如stop-the-world垃圾回收,es进程被占用,内存溢出等))此时,两个节点都会觉得对方挂了。对于节点1来说,他自己就是master,所以不需要做什么。对于节点2,因为此时集群就只有他一个节点,当他选举一个节点当master,那就只会是他自己。在elasticsearch集群,是由主节点来决定将分片平均地分布到节点上的。节点2保存的是复制分片,但它相信主节点不可用了。所以它会自动提升复制节点为主节点。那么此时,整个es集群就会出现两个master,打在节点1上的索引请求会将索引数据分配在主节点,同时打在节点2的请求会将索引数据放在分片上。也就是说,如果数据添加到es集群,就会出现分散到两个分片中,分片的两份数据分开了,不做一个全量的重索引很难对它们进行重排序。查询集群数据的请求都会成功完成,但是请求返回的结果是不同的。访问不同的节点,会发现集群状态不一样,可用节点数不一样,而且结果数据也会不一样。解决方式网络问题保证网络稳定,及时预警,重启集群。master节点负载过大可以在jvm.options中增加堆内存大小或者修改合适的GC处理器。对集群的节点做读写分离,master节点专门做集群master管理,master节点配置,同时设置一批data节点负责存储数据和处理请求。优化方法方面(ES6)discoveryzen.ping.multicast.enabled:将data节点的默认的master发现方式由multicast(多播)修改为unicast(单播),使新加入的节点快速确定master位置。discovery.zen.ping.unicast.hosts:提供其他 Elasticsearch 服务节点的单点广播发现功能。配置集群中基于主机 TCP 端口的其他 Elasticsearch 服务列表。discovery.zen.ping_timeout:节点等待响应的时间,默认值是3秒,增加这个值,会增加节点等待响应的时间,从一定程度上会减少误判。discovery.zen.minimum_master_nodes:一个节点需要看到的具有master节点资格的最小数量,然后才能在集群中做操作。官方的推荐值是(N/2)+1,其中N是具有master资格的节点的数量,设置这个参数后,只有足够的master候选节点时,才可以选举出一个master。优化方法方面(ES7)If the cluster is running with a completely default configuration then it will automatically bootstrap a cluster based on the nodes that could be discovered to be running on the same host within a short time after startup. This means that by default it is possible to start up several nodes on a single machine and have them automatically form a cluster which is very useful for development environments and experimentation. However, since nodes may not always successfully discover each other quickly enough this automatic bootstrapping cannot be relied up.译:如果集群以完全默认的配置运行,那么它将在启动后的短时间内根据可以发现在同一主机上运行的节点自动引导集群。这意味着默认情况下,可以在一台机器上启动多个节点并让它们自动形成一个集群,这对于开发环境和实验非常有用。但是,由于节点可能并不总是足够快地成功发现彼此,因此不能依赖这种自动引导,也不能在生产部署中使用。所以需要配置如下参数,让集群内的节点更快地被发现:cluster.initial_master_nodes: ["node-1", "node-2"] discovery.seed_hosts: ["host1", "host2"]discovery.seed_hosts在没有任何网络配置的情况下,Elasticsearch将直接绑定到可用的环回地址,并扫描本地端口9300到9305,以连接到同一服务器上运行的其他节点,集群中的节点能够发现彼此并选择一个主节点cluster.initial_master_nodes使用一组初始的符合主要条件的节点引导集群master 选举前提条件只有候选主节点(master:true)的节点才能成为主节点。最小主节点数(min_master_nodes)的目的是防止脑裂。实现模式第一步:确认候选主节点数达标,elasticsearch.yml 设置的值discovery.zen.minimum_master_nodes;第二步:对所有候选主节点根据nodeId字典排序,每次选举每个节点都把自己所知道节点排一次序,然后选出第一个(第0位)节点,暂且认为它是master节点。第三步:如果对某个节点的投票数达到一定的值(候选主节点数n/2+1)并且该节点自己也选举自己,那这个节点就是master。否则重新选举一直到满足上述条件。ES的读写操作ES的写操作客户端Node-1发送新建、查询或者删除文档的请求。节点根据文挡的_id为1确定文档属于分片1。因为分片1主分P-1 被分配在 Node-3 上,所以请求会被转发到 Node-3。在Node-3的主分片上执行请求,如果执行成功,则将请求同时转发到 Node-1和Node-2 的副本分片 R-1 上执行。所有副本分片都报告执行成功时, Node-3才向协调节点报告执行成功。协调节点向客户端报告成功。当客户端收到成功响应时,文档更新已经在主片和所有副本分片上都执行成功。ES的读操作流程客户端 Node-1 发送丈档读取请求协调节点Node-1 根据文档的 _id 来确定文档属于分片1。 分片1的文档数据存在所有3个节点上。在这种情况下,它将请求转发至 Node-2。Node-2在本地执行查询操作并将查询结果返回到 Node-1。Node-1(此时 Node-1为CoordinatingNode 角色)接收 Node-2 的查询结果,如果查询到请求对应的文档, 则将该文档返回客户端 如果在 Node-2 未查询到对应的文挡数据,则 Node-1 会继续向其他节点发送文档读取请求,直到查询到文档对应的数据后才返回,如果要读取的文档在所有节点上都不存在,则向客户端报告文档不存在。ES的DSL语言查询Response字段释义{ "took" : 2, #查询耗时 "timed_out" : false, #是否超时,false表示没有 "_shards" : { #分片信息,一般不用管 "total" : 5, "successful" : 5, "skipped" : 0, "failed" : 0 }, "hits" : { #查询结果:hit表示命中 "total" : 2, #本次搜索,返回了几条结果 "max_score" : 1.0, #document对于search的相关度的匹配分数,越相关,就越匹配,分数也高 "hits" : [ #结果集 { "_index" : "pethome", #查询了哪一个索引库idnex - 相当于mysql的哪一个数据库 "_type" : "pet", #查询了哪一个类型type - 相当于mysql的哪一张表,7.0已经移除 "_id" : "2", #文档id,返回哪一个文档document - 相当于mysql中的那一条数据,id为2 "_score" : 1.0, #匹配度/相关度分数score "_source" : { #源数据source "id" : 2, #字段filed - id "name" : "皮蛋", #字段filed - name "age" : 3 #字段filed - age } } ] } }常用的DSL_cat相关含义命令别名GET _cat/aliases?v分配相关GET _cat/allocation计数GET _cat/count?v字段数据GET _cat/fielddata?v运行状况GET_cat/health?索引相关GET _cat/indices?v主节点相关GET _cat/master?v节点属性GET _cat/nodeattrs?v节点GET _cat/nodes?v待处理任务GET _cat/pending_tasks?v插件GET _cat/plugins?v恢复GET _cat/recovery?v存储库GET _cat/repositories?v段GET _cat/segments?v分片GET _cat/shards?v快照GET _cat/snapshots?v任务GET _cat/tasks?v模板GET _cat/templates?v线程池GET _cat/thread_pool?vindex相关创建索引PUT /mall { "settings":{ "number_of_shards":5, //分片数:将数据分布在几个集群节点中 "number_of_replicas":1 //副本:一个分片有几个备份,对于查询压力比较的的index,可以考虑提高副本数,通过多个副本均摊压力 } }删除索引DELETE /mall文档相关查看文档mappingGET /bank/_mapping增加字段PUT /jcmall_product_sku/_mapping { "properties": { "companyMaterialNo": { "type": "keyword" } } }添加文档POST /bank/_doc { "account_number": 1, "balance": 39225, "firstname": "Amber", "lastname": "Duke", "age": 32, "gender": "M", "address": "880 Holmes Lane", "employer": "Pyrami", "email": "amberduke@pyrami.com", "city": "Brogan", "state": "IL" }批量添加POST /bank/_bulk {"index":{"_id":"1"}} {"name": "lvwei" } {"index":{"_id":"2"}} {"name": "lvwei2" }修改文档POST /bank/_update/1 { "doc": { "age": 18 } }删除文档DELETE /bank/_doc/1其他搜索# 一、群集是一个或多个节点的集合,它们一起保存整个数据,并提供跨所有节点的联合索引和搜索功能。每个群集都有自己的唯一群集名称,节点通过名称加入群集。 # 查看集群健康状态 GET /_cat/health?v # 二、节点是指属于集群的单个Elasticsearch实例,存储数据并参与集群的索引和搜索功能。可以将节点配置为按集群名称加入特定集群,默认情况下,每个节点都设置为加入一个名为elasticsearch的群集。 # 查看节点状态 GET /_cat/nodes?v # 三、Index(索引):索引是一些具有相似特征的文档集合,类似于MySql中数据库的概念 # 查看所有索引信息 GET /_cat/indices?v # 3.1 创建索引并查看 PUT /bank GET /_cat/indices?v # 3.2 删除索引并查看 DELETE /bank GET /_cat/indices?v # 四、Type(类型):类型是索引的逻辑类别分区,通常,为具有一组公共字段的文档类型,类似MySql中表的概念。注意:在Elasticsearch 6.0.0及更高的版本中,一个索引只能包含一个类型。 # 4.1 查看文档的类型 GET /bank/account/_mapping # 4.2 增加文档字段 PUT /jcmall_product_sku/_mapping { "properties": { "spec": { "type": "object", "properties": { "name": { "type": "keyword" }, "value": { "type": "text" } } }, "model": { "type": "keyword" } } } # 五、Document(文档):文档是可被索引的基本信息单位,以JSON形式表示,类似于MySql中行记录的概念。 # 5.1 在索引中添加文档 PUT /bank/_doc/2 { "name": "zhangke" } # 5.2 查看索引中的文档 GET /bank/_doc/2 # 5.3 修改索引中的文档 POST /bank/_update/1 { "doc":{"name":"lvwei5201"} } # 5.4 删除索引中的文档 DELETE /bank/_doc/1 # 5.5 对索引中的文档执行批量操作 POST /bank/_bulk {"index":{"_id":"1"}} {"name": "lvwei" } {"index":{"_id":"2"}} {"name": "zhangke" } # 六、Shards(分片):当索引存储大量数据时,可能会超出单个节点的硬件限制,为了解决这个问题,Elasticsearch提供了将索引细分为分片的概念。分片机制赋予了索引水平扩容的能力、并允许跨分片分发和并行化操作,从而提高性能和吞吐量。 # 七、Replicas(副本):在可能出现故障的网络环境中,需要有一个故障切换机制,Elasticsearch提供了将索引的分片复制为一个或多个副本的功能,副本在某些节点失效的情况下提供高可用性。 # 八、数据搜索 # 8.1 最简单的搜索,使用match_all来表示,例如搜索全部 GET /bank/_search { "query": { "match_all": {} } } # 8.2 分页搜索,from表示偏移量,从0开始,size表示每页显示的数量 GET /bank/_search { "query": { "match_all": {} } , "from": 0 , "size": 20 } # 8.3 搜索排序,使用sort表示,例如按balance字段降序排列 GET /bank/_search { "query": { "match_all": {} }, "sort": [ { "balance": { "order": "desc" } } ] } # 8.4 搜索并返回指定字段内容,使用_source表示,例如只返回account_number和balance两个字段内容: GET /bank/_search { "query": {"match_all": {}} , "_source": ["balance","account_number"] } # 8.5 条件搜索 # 8.5.1 使用match表示匹配条件,例如搜索出account_number为20的文档 GET /bank/_search { "query": {"match": { "account_number": "20" }} } # 8.5.2 文本类型字段的条件搜索,例如搜索address字段中包含mill的文档,对比上一条搜索可以发现,对于数值类型match操作使用的是精确匹配,对于文本类型使用的是模糊匹配; GET /bank/_search { "query": {"match": { "address": "mill" }} } # 8.5.2 短语匹配搜索,使用match_phrase表示,例如搜索address字段中同时包含mill和lane的文档 GET /bank/_search { "query": {"match_phrase": { "address": "mill lane" }} } # 8.6 组合搜索 # 8.6.1 组合搜索,使用bool来进行组合,must表示同时满足,例如搜索address字段中同时包含mill和lane的文档; GET /bank/_search { "query": { "bool": { "must": [ {"match": { "address": "mill" }}, {"match": { "address": "lane" }} ] } } } # 8.6.2 组合搜索,should表示满足其中任意一个,搜索address字段中包含mill或者lane的文档 GET /bank/_search { "query": { "bool": { "should": [ {"match": { "address": "mill" }}, {"match": { "address": "lane" }} ] } } } # 8.6.3 组合搜索,must_not表示同时不满足,例如搜索address字段中不包含mill且不包含lane的文档; GET /bank/_search { "query": { "bool": { "must_not": [ { "match": { "address": "mill" } }, { "match": { "address": "lane" } } ] } } } # 8.6.4 组合搜索,组合must和must_not,例如搜索age字段等于40且state字段不包含ID的文档; GET /bank/_search { "query": { "bool": { "must": [ {"match": { "age": 40 }} ], "must_not": [ {"match": { "state": "ID" }} ] } } } # 8.7 过滤搜索 # 8.7.1 搜索过滤,使用filter来表示,例如过滤出balance字段在20000~30000的文档; GET /bank/_search { "query": { "bool": { "filter": [ { "range": { "balance": { "gte": 20000, "lte": 30000 } } } ] } } } # 8.9 搜索聚合 # 8.9.1 对搜索结果进行聚合,使用aggs来表示,类似于MySql中的group by,例如对state字段进行聚合,统计出相同state的文档数量; GET /bank/_search { "size": 0, "aggs": { "group_by_state": { "terms": { "field": "state.keyword" } } } } # 8.9.2 嵌套聚合,例如对state字段进行聚合,统计出相同state的文档数量,再统计出balance的平均值; GET /bank/_search { "size": 0, "aggs": { "group_by_state": { "terms": { "field": "state.keyword" } , "aggs": { "avg_balance": { "avg": { "field": "balance" } } } } } } # 8.9.3 对聚合搜索的结果进行排序,例如按balance的平均值降序排列; GET /bank/_search { "size": 0, "aggs": { "group_by_state": { "terms": { "field": "state.keyword", "order": { "avg_balance": "desc" } } , "aggs": { "avg_balance": { "avg": { "field": "balance" } } } } } } # 8.9.4 按字段值的范围进行分段聚合,例如分段范围为age字段的[20,30] [30,40] [40,50],之后按gender统计文档个数和balance的平均值; GET /bank/_search { "size": 0, "aggs": { "group_by_age": { "range": { "field": "age", "ranges": [ { "from": 20, "to": 30 }, { "from": 30, "to": 40 },{ "from": 40, "to": 50 } ] }, "aggs": { "group_by_gender": { "terms": { "field": "gender.keyword" }, "aggs": { "avg_balance": { "avg": { "field": "balance" } } } } } } } } 电商的应用分组条件对搜索结果进行聚合,使用aggs来表示,类似于MySql中的group by,例如对state字段进行聚合,统计出相同state的文档数量.GET /bank/_search { "size": 0, "aggs": { "group_by_state": { "terms": { "field": "state.keyword" } } } }关键词高亮GET /bank/_search { "query": { "match": { "address": { "query": "mill" } } }, "highlight": { "fields": { "address": {} } } }"pre_tags":指定包裹高亮文本的前缀标签。默认为<em>。"post_tags":指定包裹高亮文本的后缀标签。默认为</em>。"fragment_size":指定每个高亮片段的最大长度(以字符为单位)。默认为100。"number_of_fragments":指定每个字段返回的最大高亮片段数。默认为5。"no_match_size":指定如果没有匹配到关键词时返回的文本长度(以字符为单位)。默认为0。"require_field_match":指定是否要求字段中的所有关键词都匹配才进行高亮。默认为true。"boundary_scanner":指定边界扫描器,用于确定高亮片段的边界。可用选项包括"chars"、"sentence"和"word"等。这些属性可以根据您的需求进行适当的配置。例如,如果您希望自定义前缀和后缀标签,您可以将"pre_tags"和"post_tags"设置为您喜欢的HTML标签。以下是一个示例,展示了如何使用一些常见的配置选项:json复制代码"highlight": { "fields": { "address": { "pre_tags": ["<strong>"], "post_tags": ["</strong>"], "fragment_size": 50, "number_of_fragments": 2 } } }这个示例将在高亮文本周围使用<strong>和</strong>标签,每个片段最多显示50个字符,每个字段最多返回2个高亮片段。
ElasticSearch 分享 ES的基本概念ES的介绍Elasticsearch 是一个分布式、Restful风格、基于 Apache Lucene 的分布式搜索引擎,由elastic公司开发并基于Apache许可条款发布源码。其核心功能可以用两个词来概括:搜索(search)和分析(analysis)。Elasticsearch 为所有的数据类型提供了近乎实时的搜索和分析功能。无论数据类型是结构化文本还是非结构化文本,数字类型或者地理数据类型等,Elasticsearch 都能高效的进行存储,并且以一定的方式构建索引来实现快速搜索。而且因为其天生的分布式特性,数据量增大的同时,部署也可以无缝升级。Elasticsearch索引的精髓:一切设计都是为了提高搜索的性能。2013年初,GitHub抛弃了Solr,采取ElasticSearch 来做PB级的搜索。 GitHub使用ElasticSearch搜索20TB的数据,包括13亿文件和1300亿行代码维基百科:启动以elasticsearch为基础的核心搜索架构SoundCloud:SoundCloud使用ElasticSearch为1.8亿用户提供即时而精准的音乐搜索服务百度:百度目前广泛使用ElasticSearch作为文本数据分析,采集百度所有服务器上的各类指标数据及用户自定义数据,通过对各种数据进行多维分析展示,辅助定位分析实例异常或业务层面异常。目前覆盖百度内部20多个业务线(包括casio、云分析、网盟、预测、文库、直达号、钱包、风控等),单集群最大100台机器,200个ES节点,每天导入30TB+数据新浪使用ES 分析处理32亿条实时日志阿里使用ES 构建挖财自己的日志采集和分析体系ES和lucene的区别Lucene只支持Java,ES支持多种语言。Lucene非分布式,ES支持分布式。Lucene非分布式的,索引目录只能在项目本地 , ES的索引库可以跨多个服务分片存储。Lucene使用非常复杂,ES屏蔽了Lucene的使用细节,操作更方便。单体/小项目使用Lucene ,大项目或分布式项目使用ES。ES的竞品分析Solr:Solr 利用 Zookeeper(注册中心) 进行分布式管理,支持更多格式的数据(HTML/PDF/CSV),官方提供的功能更多在传统的搜索应用中表现好于 ES,但实时搜索效率低。ES自身带有分布式协调管理功能,但仅支持json文件格式,本身更注重于核心功能,高级功能多有第三方插件提供,在处理实时搜索应用时效率明显高于 Solr。Solr 利用 Zookeeper 进行分布式管理,而 Elasticsearch 自身带有分布式协调管理功能;Solr 支持更多格式的数据,而 Elasticsearch 仅支持json文件格式;Solr 官方提供的功能更多,而 Elasticsearch 本身更注重于核心功能,高级功能多有第三方插件提供;Solr 在传统的搜索应用中表现好于 Elasticsearch,但在处理实时搜索应用时效率明显低于 ElasticsearchKatta:基于 Lucene 的,支持分布式,可扩展,具有容错功能,准实时的搜索方案。优点:开箱即用,可以与 Hadoop (大数据)配合实现分布式。具备扩展和容错机制。缺点:只是搜索方案,建索引部分还是需要自己实现。在搜索功能上,只实现了最基本的需求。成功案例较少,项目的成熟度稍微差一些。HadoopContrib:Map/Reduce 模式(云计算)的,分布式建索引方案,可以跟 Katta 配合使用。优点:分布式建索引,具备可扩展性。缺点:只是建索引方案,不包括搜索实现。工作在批处理模式,对实时搜索的支持不佳。ES的特点高容量:集群支持PB级数据的存储和查询。高吞吐:支持对海量数据近实时的数据处理。高可用:基于副本机制支持部分服务宕机后仍可正常运行和使用。支持多维度数据分析和处理:除了支持全文检索, 还支持基于单字段精确查询和多字段联合查询等复杂的数据查询操作。API 简单易用: API 简单易用,除了支持 RestfulApi,还支持 Java、Python 等多客户端形式,且查方式简单灵活。支持插件机制: 支持插件式开发,基于 ElasticSearch 可以开发自己的分词插件、同步插件、 Hadoop 捅件 可视化插件。ES的应用场景全文检索:底层基于 Lucene 实现 ,十分适合类 百度百科、维基百科等全文检索的应用场景分布式数据库: 可作为分布式数据库,为大数据云计算提供数据存储和查询服务,广泛应用于淘宝、 京东等电商平台的商品管理和检索服务日志分析:通 logstash 日志采集组件,可实现复杂的日志数据存储分析和查询,最常用的组合是 ELK ( ElasticSearch、Logstash、Kibana )技术组合运维监控:运维平台可以 ElasticSearch 实现大规模服务的监控和管理BI系统:广泛应用于 ( Business Intelligence ,商业智能)系统,例如按照区域统计用户的操作习惯等。Lucene的介绍Lucene架构倒排索引在实际应用中,我们常常需要根据属性的值来查找记录,这时就需要使用倒排索引 ( Inverted Index )。 倒排索引表中的每一项都包括一个属性值和具有该属性值对应记录的地址,由于不是按照记录来确定属性值的,而是由属性值来确定记录的位置的,因此被称为倒排索引。例如,当我们在百度搜索栏中输入关键词时,百度会按照输入的关键词,在所有文档内容(比如网页内容)中搜索与关键词相关的记录(比如网站),并将内容相关的记录的地址(比如网站的地址)返回用户,然后用户便可按该记录的地址进一步查看记录的详细信息。搜索引擎的关键是建立倒排索引,倒排索引一般表示一个关键词,以及它的频度 (出现的次数)和位置(出现在哪一篇文章或网页中,以及相关的日期、作者等信息) 带有倒排索引的文件被称为倒排索引文件( Inverted File ), 倒排索引的索引对象是文档或者文档集合中的单词,倒排索引文件被用来存储这些单词在一个文档或者一组文档中的位置。倒排索引数据结构倒排索引的核心分为两部分:单词词典(Term Dictionary):记录所有文档的单词以及单词到倒排列表的关联关系,实际生产中,单词量会非常大,所以实际会采用 B+ 树和哈希拉链法去存储单词的词典,以满足高性能的插入与查询。倒排列表(Posting List):它记录了单词对应文档的结合,倒排列表是由倒排索引项(Posting) 组成,倒排索引项包含:文档 ID:用于获取原始信息词频(TF,Term Frequency):该单词在文档中出现的次数,用于相关性评分位置(Position):单词在文档中分词的位置,用于语句搜索(Phrase Query)偏移(Offset):记录单词的开始结束位置,实现高亮显示(比如用 GitHub 搜索的时候,搜索的关键词会高亮显示)一个倒排索引是由单词词典(Term Dictionary)和倒排列表(Posting List)组成的,单词词典会记录倒排列表中每个单词的偏移位置。比如当搜索 Allen 的时候,首先会通过单词词典快速定位到 Allen,然后从 Allen 这里拿到在倒排列表中的偏移,快速定位到在倒排列表中的位置,从而真正拿到倒排索引项 [12,15](这里只是列了下 Document ID,其实是像上面讲的包含 4 项信息的项),拿到这个项可以去索引上拿到原始信息,可以去计算打分排序返回给用户。全文检索流程常用术语索引(index):相当于关系型数据库中的数据库,8.x 不再支持type,所以索引也可以看作为数据库中的表。一个索引就是一个拥有几分相似特征的文档的集合。比如说,你可以有一个客户数据的索引,另一个产品目录的索引,还有一个订单数据的索引。一个索引由一个名字来标识(必须全部是小写字母),并且当我们要对这个索引中的文档进行索引、搜索、更新和删除的时候,都要使用到这个名字。在一个集群中,可以定义任意多的索引。能搜索的数据必须索引,这样的好处是可以提高查询速度,比如:新华字典前面的目录就是索引的意思,目录可以提高查询速度。类型(type):相当于传统数据库中的表。这个在 7.x 版本中已经被标注过期,在 8.x 版本中不再支持。7.x 之后默认类型为:_doc。文档(document):相当于关系型数据库中的一行数据。文档以JSON格式来表示,在一个index/type里面,你可以存储任意多的文档。域(field):相当于关系型数据库中的字段,对文档数据根据不同属性进行的分类标识。映射(mapping):相当于传统数据库中的建表语句,可以设置一些列中的数据类型及其他一些特性,如果不设置 mapping,则会默认创建。默认情况下,Elasticsearch中的每个索引被分片5个主分片和1个复制,这意味着,如果你的集群中至少有两个节点,你的索引将会有5个主分片和另外5个复制分片(1个完全拷贝),这样的话每个索引总共就有10个分片。mapping映射mapping是处理数据的方式和规则方面做一些限制,如:某个字段的数据类型、默认值、分析器、是否被索引等等。这些都是映射里面可以设置的,其它就是处理ES里面数据的一些使用规则设置也叫做映射,按着最优规则处理数据对性能提高很大,因此才需要建立映射,并且需要思考如何建立映射才能对性能更好。mapping作用定义索引中的字段的名称定义字段的数据类型,比如字符串、数字、布尔字段,倒排索引的相关配置,比如设置某个字段为不被索引、记录 position 等简单的定义示例{ "mappings": { "_doc": { "dynamic": false }, "properties": { "productId": { //商品ID "type": "long" }, "price": { //商品价格 "type": "keyword" }, "discountPrice": { //商品折扣价格 "type": "keyword" }, "productName": { //商品名称 "type": "text", "analyzer": "ik_smart" //按照ik_smart进行分词 }, "productImg": { //商品图片 "type": "text", "index": false, //不允许被查询 "doc_values": false //不允许被聚合 }, "brandId": { //品牌ID "type": "long" }, "brandName": { //品牌名称 "type": "keyword" }, "oneCategoryId": { //一级分类ID "type": "long" }, "oneCategoryName": { //一级分类名称 "type": "keyword" }, "twoCategoryId": { //二级分类ID "type": "long" }, "twoCategoryName": { //一级分类名称 "type": "keyword" }, "lockCnt": { //热销 "type": "long" }, "publishStatus": { //状态 "type": "long" }, "productEffect": { //功效 "type": "nested", //防止在es库中被扁平处理 "properties": { "productEffectId": { "type": "long" }, "productEffectName": { "type": "keyword" } } }, "skin": { //肤质 "type": "nested", "properties": { "skinId": { "type": "long" }, "skinName": { "type": "keyword" } } } } } }在创建一个索引的时候,可以对 dynamic 进行设置,可以设成 false、true 或者 strict。如果是新增加的字段,根据 Dynamic 的设置分为以下三种状况:当 Dynamic 设置为 true 时,一旦有新增字段的文档写入,Mapping 也同时被更新。当 Dynamic 设置为 false 时,索引的 Mapping 是不会被更新的,新增字段的数据无法被索引,也就是无法被搜索,但是信息会出现在 _source 中。当 Dynamic 设置为 strict 时,文档写入会失败。另外一种是字段已经存在,这种情况下,ES 是不允许修改字段的类型的,因为 ES 是根据 Lucene 实现的倒排索引,一旦生成后就不允许修改,如果希望改变字段类型,必须使用 Reindex API 重建索引。不能修改的原因是如果修改了字段的数据类型,会导致已被索引的无法被搜索,但是如果是增加新的字段,就不会有这样的影响。mapping设置数据类型ES 字段类型主要有:核心类型、复杂类型、地理类型以及特殊类型。注意项:text 类型适用于需要被全文检索的字段,例如新闻正文、邮件内容、商品名称、公告内容等比较长的文字,text 类型会被 Lucene 分词器(Analyzer)处理为一个个词项,并使用 Lucene 倒排索引存储,text 字段不能被用于排序,如果需要使用该类型的字段只需要在定义映射时指定 JSON 中对应字段的 type 为 text。keyword 适合简短、结构化字符串,例如品牌、姓名、生产地、邮箱、ip等通常不需要拆的数据,可以用于过滤、排序、聚合检索,也可以用于精确查询。对象类型JSON 字符串允许嵌套对象,一个文档可以嵌套多个、多层对象。可以通过对象类型来存储二级文档,不过由于 Lucene 并没有内部对象的概念,ES 会将原 JSON 文档扁平化,例如文档{ "name": { "first": "zhang", "last": "yong } }实际上 ES 会将其转换为以下格式,并通过 Lucene 存储,即使 name 是 object 类型:{ "name.first": "zhang", "name.last": "yong" }嵌套类型嵌套类型可以看成是一个特殊的对象类型,可以让对象数组独立检索,例如文档:{ "group": "users", "username": [ { "first": "lv", "last": "wei"}, { "first": "zhang", "last": "san"}, { "first": "li", "last": "si"} ] }username 字段是一个 JSON 数组,并且每个数组对象都是一个 JSON 对象。如果将 username 设置为对象类型,那么 ES 会将其转换为:{ "group": "users", "username.first": ["lv", "zhang", "li"], "username.last": ["wei", "san", "si"] }可以看出转换后的 JSON 文档中 first 和 last 的关联丢失了,如果尝试搜索 first 为 lv,last 为 wei 的文档,那么成功会检索出上述文档,但是 lv 和 wei 在原 JSON 文档中并不属于同一个 JSON 对象,应当是不匹配的,即检索不出任何结果。嵌套类型就是为了解决这种问题的,嵌套类型将数组中的每个 JSON 对象作为独立的隐藏文档来存储,每个嵌套的对象都能够独立地被搜索,所以上述案例中虽然表面上只有 1 个文档,但实际上是存储了 4 个文档。Dynamic MappingDynamic Mapping 机制使我们不需要手动定义 Mapping,ES 会自动根据文档信息来判断字段合适的类型,但是有时候也会推算的不对,比如地理位置信息有可能会判断为 Text,当类型如果设置不对时,会导致一些功能无法正常工作,比如 Range 查询。ES 类型的自动识别是基于 JSON 的格式,如果输入的是 JSON 是字符串且格式为日期格式,ES 会自动设置成 Date 类型;当输入的字符串是数字的时候,ES 默认会当成字符串来处理,可以通过设置来转换成合适的类型;如果输入的是 Text 字段的时候,ES 会自动增加 keyword 子字段,还有一些自动识别如下图所示:ES的集群相关集群的架构master node:整个集群的管理者,索引管理,分片管理,以及整个集群的状态的管理,master节点是从master候选节点中选出的,成为master候选节点的方式: node.master:true 默认(true)data node:数据节点,存储主要数据,负责索引的数据的检索和聚合等操作,成为data node的方式: node.data:true 默认(true)coordinating node:协调节点,所有节点都可以接受来自客户端的请求进行转发,因为每个节点都知道集群的所有索引分片的分布情况,但是别的节点,都还肩负着别的工作,如果请求压力过大,可能会拖垮整个集群的响应速度,所以就专门有了这个协调节点,他什么都不用做,只处理请求和请求结果,所以成为coordinating node的方式: node.data:false node.master:falseingest node:预处理节点,主要是对数据进行预处理,比如对字段重命名,分解字段内容,增加字段等,类似于Logstash, 就是对数据进行预处理,ingest里面可以定义pipeline(管道),pipeline可以由很多个processor(官方预定义28个)构成,用来出来预处理数据,使用方式:先定义好预处理pipeline,然后在存储数据的时候指定pipeline,如:成为ingest node的方式: node.ingest:true 默认(true)脑裂问题产生原因集群维护一个单个索引并有一个分片和一个复制节点。节点1在启动时被选举为主节点并保存主分片(在下面的schema里标记为0P),而节点2保存复制分片(0R)。这时如果在两个节点之间的通讯中断了(网络问题或只是因为其中一个节点无响应(例如stop-the-world垃圾回收,es进程被占用,内存溢出等))此时,两个节点都会觉得对方挂了。对于节点1来说,他自己就是master,所以不需要做什么。对于节点2,因为此时集群就只有他一个节点,当他选举一个节点当master,那就只会是他自己。在elasticsearch集群,是由主节点来决定将分片平均地分布到节点上的。节点2保存的是复制分片,但它相信主节点不可用了。所以它会自动提升复制节点为主节点。那么此时,整个es集群就会出现两个master,打在节点1上的索引请求会将索引数据分配在主节点,同时打在节点2的请求会将索引数据放在分片上。也就是说,如果数据添加到es集群,就会出现分散到两个分片中,分片的两份数据分开了,不做一个全量的重索引很难对它们进行重排序。查询集群数据的请求都会成功完成,但是请求返回的结果是不同的。访问不同的节点,会发现集群状态不一样,可用节点数不一样,而且结果数据也会不一样。解决方式网络问题保证网络稳定,及时预警,重启集群。master节点负载过大可以在jvm.options中增加堆内存大小或者修改合适的GC处理器。对集群的节点做读写分离,master节点专门做集群master管理,master节点配置,同时设置一批data节点负责存储数据和处理请求。优化方法方面(ES6)discoveryzen.ping.multicast.enabled:将data节点的默认的master发现方式由multicast(多播)修改为unicast(单播),使新加入的节点快速确定master位置。discovery.zen.ping.unicast.hosts:提供其他 Elasticsearch 服务节点的单点广播发现功能。配置集群中基于主机 TCP 端口的其他 Elasticsearch 服务列表。discovery.zen.ping_timeout:节点等待响应的时间,默认值是3秒,增加这个值,会增加节点等待响应的时间,从一定程度上会减少误判。discovery.zen.minimum_master_nodes:一个节点需要看到的具有master节点资格的最小数量,然后才能在集群中做操作。官方的推荐值是(N/2)+1,其中N是具有master资格的节点的数量,设置这个参数后,只有足够的master候选节点时,才可以选举出一个master。优化方法方面(ES7)If the cluster is running with a completely default configuration then it will automatically bootstrap a cluster based on the nodes that could be discovered to be running on the same host within a short time after startup. This means that by default it is possible to start up several nodes on a single machine and have them automatically form a cluster which is very useful for development environments and experimentation. However, since nodes may not always successfully discover each other quickly enough this automatic bootstrapping cannot be relied up.译:如果集群以完全默认的配置运行,那么它将在启动后的短时间内根据可以发现在同一主机上运行的节点自动引导集群。这意味着默认情况下,可以在一台机器上启动多个节点并让它们自动形成一个集群,这对于开发环境和实验非常有用。但是,由于节点可能并不总是足够快地成功发现彼此,因此不能依赖这种自动引导,也不能在生产部署中使用。所以需要配置如下参数,让集群内的节点更快地被发现:cluster.initial_master_nodes: ["node-1", "node-2"] discovery.seed_hosts: ["host1", "host2"]discovery.seed_hosts在没有任何网络配置的情况下,Elasticsearch将直接绑定到可用的环回地址,并扫描本地端口9300到9305,以连接到同一服务器上运行的其他节点,集群中的节点能够发现彼此并选择一个主节点cluster.initial_master_nodes使用一组初始的符合主要条件的节点引导集群master 选举前提条件只有候选主节点(master:true)的节点才能成为主节点。最小主节点数(min_master_nodes)的目的是防止脑裂。实现模式第一步:确认候选主节点数达标,elasticsearch.yml 设置的值discovery.zen.minimum_master_nodes;第二步:对所有候选主节点根据nodeId字典排序,每次选举每个节点都把自己所知道节点排一次序,然后选出第一个(第0位)节点,暂且认为它是master节点。第三步:如果对某个节点的投票数达到一定的值(候选主节点数n/2+1)并且该节点自己也选举自己,那这个节点就是master。否则重新选举一直到满足上述条件。ES的读写操作ES的写操作客户端Node-1发送新建、查询或者删除文档的请求。节点根据文挡的_id为1确定文档属于分片1。因为分片1主分P-1 被分配在 Node-3 上,所以请求会被转发到 Node-3。在Node-3的主分片上执行请求,如果执行成功,则将请求同时转发到 Node-1和Node-2 的副本分片 R-1 上执行。所有副本分片都报告执行成功时, Node-3才向协调节点报告执行成功。协调节点向客户端报告成功。当客户端收到成功响应时,文档更新已经在主片和所有副本分片上都执行成功。ES的读操作流程客户端 Node-1 发送丈档读取请求协调节点Node-1 根据文档的 _id 来确定文档属于分片1。 分片1的文档数据存在所有3个节点上。在这种情况下,它将请求转发至 Node-2。Node-2在本地执行查询操作并将查询结果返回到 Node-1。Node-1(此时 Node-1为CoordinatingNode 角色)接收 Node-2 的查询结果,如果查询到请求对应的文档, 则将该文档返回客户端 如果在 Node-2 未查询到对应的文挡数据,则 Node-1 会继续向其他节点发送文档读取请求,直到查询到文档对应的数据后才返回,如果要读取的文档在所有节点上都不存在,则向客户端报告文档不存在。ES的DSL语言查询Response字段释义{ "took" : 2, #查询耗时 "timed_out" : false, #是否超时,false表示没有 "_shards" : { #分片信息,一般不用管 "total" : 5, "successful" : 5, "skipped" : 0, "failed" : 0 }, "hits" : { #查询结果:hit表示命中 "total" : 2, #本次搜索,返回了几条结果 "max_score" : 1.0, #document对于search的相关度的匹配分数,越相关,就越匹配,分数也高 "hits" : [ #结果集 { "_index" : "pethome", #查询了哪一个索引库idnex - 相当于mysql的哪一个数据库 "_type" : "pet", #查询了哪一个类型type - 相当于mysql的哪一张表,7.0已经移除 "_id" : "2", #文档id,返回哪一个文档document - 相当于mysql中的那一条数据,id为2 "_score" : 1.0, #匹配度/相关度分数score "_source" : { #源数据source "id" : 2, #字段filed - id "name" : "皮蛋", #字段filed - name "age" : 3 #字段filed - age } } ] } }常用的DSL_cat相关含义命令别名GET _cat/aliases?v分配相关GET _cat/allocation计数GET _cat/count?v字段数据GET _cat/fielddata?v运行状况GET_cat/health?索引相关GET _cat/indices?v主节点相关GET _cat/master?v节点属性GET _cat/nodeattrs?v节点GET _cat/nodes?v待处理任务GET _cat/pending_tasks?v插件GET _cat/plugins?v恢复GET _cat/recovery?v存储库GET _cat/repositories?v段GET _cat/segments?v分片GET _cat/shards?v快照GET _cat/snapshots?v任务GET _cat/tasks?v模板GET _cat/templates?v线程池GET _cat/thread_pool?vindex相关创建索引PUT /mall { "settings":{ "number_of_shards":5, //分片数:将数据分布在几个集群节点中 "number_of_replicas":1 //副本:一个分片有几个备份,对于查询压力比较的的index,可以考虑提高副本数,通过多个副本均摊压力 } }删除索引DELETE /mall文档相关查看文档mappingGET /bank/_mapping增加字段PUT /jcmall_product_sku/_mapping { "properties": { "companyMaterialNo": { "type": "keyword" } } }添加文档POST /bank/_doc { "account_number": 1, "balance": 39225, "firstname": "Amber", "lastname": "Duke", "age": 32, "gender": "M", "address": "880 Holmes Lane", "employer": "Pyrami", "email": "amberduke@pyrami.com", "city": "Brogan", "state": "IL" }批量添加POST /bank/_bulk {"index":{"_id":"1"}} {"name": "lvwei" } {"index":{"_id":"2"}} {"name": "lvwei2" }修改文档POST /bank/_update/1 { "doc": { "age": 18 } }删除文档DELETE /bank/_doc/1其他搜索# 一、群集是一个或多个节点的集合,它们一起保存整个数据,并提供跨所有节点的联合索引和搜索功能。每个群集都有自己的唯一群集名称,节点通过名称加入群集。 # 查看集群健康状态 GET /_cat/health?v # 二、节点是指属于集群的单个Elasticsearch实例,存储数据并参与集群的索引和搜索功能。可以将节点配置为按集群名称加入特定集群,默认情况下,每个节点都设置为加入一个名为elasticsearch的群集。 # 查看节点状态 GET /_cat/nodes?v # 三、Index(索引):索引是一些具有相似特征的文档集合,类似于MySql中数据库的概念 # 查看所有索引信息 GET /_cat/indices?v # 3.1 创建索引并查看 PUT /bank GET /_cat/indices?v # 3.2 删除索引并查看 DELETE /bank GET /_cat/indices?v # 四、Type(类型):类型是索引的逻辑类别分区,通常,为具有一组公共字段的文档类型,类似MySql中表的概念。注意:在Elasticsearch 6.0.0及更高的版本中,一个索引只能包含一个类型。 # 4.1 查看文档的类型 GET /bank/account/_mapping # 4.2 增加文档字段 PUT /jcmall_product_sku/_mapping { "properties": { "spec": { "type": "object", "properties": { "name": { "type": "keyword" }, "value": { "type": "text" } } }, "model": { "type": "keyword" } } } # 五、Document(文档):文档是可被索引的基本信息单位,以JSON形式表示,类似于MySql中行记录的概念。 # 5.1 在索引中添加文档 PUT /bank/_doc/2 { "name": "zhangke" } # 5.2 查看索引中的文档 GET /bank/_doc/2 # 5.3 修改索引中的文档 POST /bank/_update/1 { "doc":{"name":"lvwei5201"} } # 5.4 删除索引中的文档 DELETE /bank/_doc/1 # 5.5 对索引中的文档执行批量操作 POST /bank/_bulk {"index":{"_id":"1"}} {"name": "lvwei" } {"index":{"_id":"2"}} {"name": "zhangke" } # 六、Shards(分片):当索引存储大量数据时,可能会超出单个节点的硬件限制,为了解决这个问题,Elasticsearch提供了将索引细分为分片的概念。分片机制赋予了索引水平扩容的能力、并允许跨分片分发和并行化操作,从而提高性能和吞吐量。 # 七、Replicas(副本):在可能出现故障的网络环境中,需要有一个故障切换机制,Elasticsearch提供了将索引的分片复制为一个或多个副本的功能,副本在某些节点失效的情况下提供高可用性。 # 八、数据搜索 # 8.1 最简单的搜索,使用match_all来表示,例如搜索全部 GET /bank/_search { "query": { "match_all": {} } } # 8.2 分页搜索,from表示偏移量,从0开始,size表示每页显示的数量 GET /bank/_search { "query": { "match_all": {} } , "from": 0 , "size": 20 } # 8.3 搜索排序,使用sort表示,例如按balance字段降序排列 GET /bank/_search { "query": { "match_all": {} }, "sort": [ { "balance": { "order": "desc" } } ] } # 8.4 搜索并返回指定字段内容,使用_source表示,例如只返回account_number和balance两个字段内容: GET /bank/_search { "query": {"match_all": {}} , "_source": ["balance","account_number"] } # 8.5 条件搜索 # 8.5.1 使用match表示匹配条件,例如搜索出account_number为20的文档 GET /bank/_search { "query": {"match": { "account_number": "20" }} } # 8.5.2 文本类型字段的条件搜索,例如搜索address字段中包含mill的文档,对比上一条搜索可以发现,对于数值类型match操作使用的是精确匹配,对于文本类型使用的是模糊匹配; GET /bank/_search { "query": {"match": { "address": "mill" }} } # 8.5.2 短语匹配搜索,使用match_phrase表示,例如搜索address字段中同时包含mill和lane的文档 GET /bank/_search { "query": {"match_phrase": { "address": "mill lane" }} } # 8.6 组合搜索 # 8.6.1 组合搜索,使用bool来进行组合,must表示同时满足,例如搜索address字段中同时包含mill和lane的文档; GET /bank/_search { "query": { "bool": { "must": [ {"match": { "address": "mill" }}, {"match": { "address": "lane" }} ] } } } # 8.6.2 组合搜索,should表示满足其中任意一个,搜索address字段中包含mill或者lane的文档 GET /bank/_search { "query": { "bool": { "should": [ {"match": { "address": "mill" }}, {"match": { "address": "lane" }} ] } } } # 8.6.3 组合搜索,must_not表示同时不满足,例如搜索address字段中不包含mill且不包含lane的文档; GET /bank/_search { "query": { "bool": { "must_not": [ { "match": { "address": "mill" } }, { "match": { "address": "lane" } } ] } } } # 8.6.4 组合搜索,组合must和must_not,例如搜索age字段等于40且state字段不包含ID的文档; GET /bank/_search { "query": { "bool": { "must": [ {"match": { "age": 40 }} ], "must_not": [ {"match": { "state": "ID" }} ] } } } # 8.7 过滤搜索 # 8.7.1 搜索过滤,使用filter来表示,例如过滤出balance字段在20000~30000的文档; GET /bank/_search { "query": { "bool": { "filter": [ { "range": { "balance": { "gte": 20000, "lte": 30000 } } } ] } } } # 8.9 搜索聚合 # 8.9.1 对搜索结果进行聚合,使用aggs来表示,类似于MySql中的group by,例如对state字段进行聚合,统计出相同state的文档数量; GET /bank/_search { "size": 0, "aggs": { "group_by_state": { "terms": { "field": "state.keyword" } } } } # 8.9.2 嵌套聚合,例如对state字段进行聚合,统计出相同state的文档数量,再统计出balance的平均值; GET /bank/_search { "size": 0, "aggs": { "group_by_state": { "terms": { "field": "state.keyword" } , "aggs": { "avg_balance": { "avg": { "field": "balance" } } } } } } # 8.9.3 对聚合搜索的结果进行排序,例如按balance的平均值降序排列; GET /bank/_search { "size": 0, "aggs": { "group_by_state": { "terms": { "field": "state.keyword", "order": { "avg_balance": "desc" } } , "aggs": { "avg_balance": { "avg": { "field": "balance" } } } } } } # 8.9.4 按字段值的范围进行分段聚合,例如分段范围为age字段的[20,30] [30,40] [40,50],之后按gender统计文档个数和balance的平均值; GET /bank/_search { "size": 0, "aggs": { "group_by_age": { "range": { "field": "age", "ranges": [ { "from": 20, "to": 30 }, { "from": 30, "to": 40 },{ "from": 40, "to": 50 } ] }, "aggs": { "group_by_gender": { "terms": { "field": "gender.keyword" }, "aggs": { "avg_balance": { "avg": { "field": "balance" } } } } } } } } 电商的应用分组条件对搜索结果进行聚合,使用aggs来表示,类似于MySql中的group by,例如对state字段进行聚合,统计出相同state的文档数量.GET /bank/_search { "size": 0, "aggs": { "group_by_state": { "terms": { "field": "state.keyword" } } } }关键词高亮GET /bank/_search { "query": { "match": { "address": { "query": "mill" } } }, "highlight": { "fields": { "address": {} } } }"pre_tags":指定包裹高亮文本的前缀标签。默认为<em>。"post_tags":指定包裹高亮文本的后缀标签。默认为</em>。"fragment_size":指定每个高亮片段的最大长度(以字符为单位)。默认为100。"number_of_fragments":指定每个字段返回的最大高亮片段数。默认为5。"no_match_size":指定如果没有匹配到关键词时返回的文本长度(以字符为单位)。默认为0。"require_field_match":指定是否要求字段中的所有关键词都匹配才进行高亮。默认为true。"boundary_scanner":指定边界扫描器,用于确定高亮片段的边界。可用选项包括"chars"、"sentence"和"word"等。这些属性可以根据您的需求进行适当的配置。例如,如果您希望自定义前缀和后缀标签,您可以将"pre_tags"和"post_tags"设置为您喜欢的HTML标签。以下是一个示例,展示了如何使用一些常见的配置选项:json复制代码"highlight": { "fields": { "address": { "pre_tags": ["<strong>"], "post_tags": ["</strong>"], "fragment_size": 50, "number_of_fragments": 2 } } }这个示例将在高亮文本周围使用<strong>和</strong>标签,每个片段最多显示50个字符,每个字段最多返回2个高亮片段。 -
10 种超赞的 MyBatis 写法 MyBatis 虽说给我们的开发带来了很多的便捷,但有些地方写起来依旧比较的麻烦,比如配置XML的时候,但是一个好的写法,不仅能为我们节省不少时间、还能能降低出错的概率,下面就给大家分享一些优质的写法:1、用来循环容器的标签forEachforeach元素的属性主要有item,index,collection,open,separator,close。item:集合中元素迭代时的别名,index:集合中元素迭代时的索引open:常用语where语句中,表示以什么开始,比如以'('开始separator:表示在每次进行迭代时的分隔符,close 常用语where语句中,表示以什么结束,在使用foreach的时候最关键的也是最容易出错的就是collection属性,该属性是必须指定的,但是在不同情况下,该属性的值是不一样的,主要有一下3种情况:如果传入的是单参数且参数类型是一个List的时候,collection属性值为list .如果传入的是单参数且参数类型是一个array数组的时候,collection的属性值为array .如果传入的参数是多个的时候,我们就需要把它们封装成一个Map了,当然单参数也可以封装成map,实际上如果你在传入参数的时候,在MyBatis里面也是会把它封装成一个Map的,map的key就是参数名,所以这个时候collection属性值就是传入的List或array对象在自己封装的map里面的key.针对最后一条,我们来看一下官方说法:注意 你可以将一个 List 实例或者数组作为参数对象传给 MyBatis,当你这么做的时候,MyBatis 会自动将它包装在一个 Map 中并以名称为键。List 实例将会以“list”作为键,而数组实例的键将是“array”。所以,不管是多参数还是单参数的list,array类型,都可以封装为map进行传递。如果传递的是一个List,则mybatis会封装为一个list为key,list值为object的map,如果是array,则封装成一个array为key,array的值为object的map,如果自己封装呢,则colloection里放的是自己封装的map里的key值//mapper中我们要为这个方法传递的是一个容器,将容器中的元素一个一个的 //拼接到xml的方法中就要使用这个forEach这个标签了 public List<Entity> queryById(List<String> userids); //对应的xml中如下 <select id="queryById" resultMap="BaseReslutMap" > select * FROM entity where id in <foreach collection="userids" item="userid" index="index" open="(" separator="," close=")"> #{userid} </foreach> </select> 2、concat模糊查询//比如说我们想要进行条件查询,但是几个条件不是每次都要使用,那么我们就可以 //通过判断是否拼接到sql中 <select id="queryById" resultMap="BascResultMap" parameterType="entity"> SELECT * from entity <where> <if test="name!=null"> name like concat('%',concat(#{name},'%')) </if> </where> </select>3、choose (when, otherwise)标签choose标签是按顺序判断其内部when标签中的test条件出否成立,如果有一个成立,则 choose 结束。当 choose 中所有 when 的条件都不满则时,则执行 otherwise 中的sql。类似于Java 的 switch 语句,choose 为 switch,when 为 case,otherwise 则为 default。例如下面例子,同样把所有可以限制的条件都写上,方面使用。choose会从上到下选择一个when标签的test为true的sql执行。安全考虑,我们使用where将choose包起来,放置关键字多于错误。<!-- choose(判断参数) - 按顺序将实体类 User 第一个不为空的属性作为:where条件 --> <select id="getUserList_choose" resultMap="resultMap_user" parameterType="com.yiibai.pojo.User"> SELECT * FROM User u <where> <choose> <when test="username !=null "> u.username LIKE CONCAT(CONCAT('%', #{username, jdbcType=VARCHAR}),'%') </when > <when test="sex != null and sex != '' "> AND u.sex = #{sex, jdbcType=INTEGER} </when > <when test="birthday != null "> AND u.birthday = #{birthday, jdbcType=DATE} </when > <otherwise> </otherwise> </choose> </where> </select> 4、selectKey 标签在insert语句中,在Oracle经常使用序列、在MySQL中使用函数来自动生成插入表的主键,而且需要方法能返回这个生成主键。使用myBatis的selectKey标签可以实现这个效果。下面例子,使用mysql数据库自定义函数nextval('student'),用来生成一个key,并把他设置到传入的实体类中的studentId属性上。所以在执行完此方法后,边可以通过这个实体类获取生成的key。<!-- 插入学生 自动主键--> <insert id="createStudentAutoKey" parameterType="liming.student.manager.data.model.StudentEntity" keyProperty="studentId"> <selectKey keyProperty="studentId" resultType="String" order="BEFORE"> select nextval('student') </selectKey> INSERT INTO STUDENT_TBL(STUDENT_ID, STUDENT_NAME, STUDENT_SEX, STUDENT_BIRTHDAY, STUDENT_PHOTO, CLASS_ID, PLACE_ID) VALUES (#{studentId}, #{studentName}, #{studentSex}, #{studentBirthday}, #{studentPhoto, javaType=byte[], jdbcType=BLOB, typeHandler=org.apache.ibatis.type.BlobTypeHandler}, #{classId}, #{placeId}) </insert> 调用接口方法,和获取自动生成keyStudentEntity entity = new StudentEntity(); entity.setStudentName("黎明你好"); entity.setStudentSex(1); entity.setStudentBirthday(DateUtil.parse("1985-05-28")); entity.setClassId("20000001"); entity.setPlaceId("70000001"); this.dynamicSqlMapper.createStudentAutoKey(entity); System.out.println("新增学生ID: " + entity.getStudentId()); 5、if标签if标签可用在许多类型的sql语句中,我们以查询为例。首先看一个很普通的查询:<!-- 查询学生list,like姓名 --> <select id="getStudentListLikeName" parameterType="StudentEntity" resultMap="studentResultMap"> SELECT * from STUDENT_TBL ST WHERE ST.STUDENT_NAME LIKE CONCAT(CONCAT('%', #{studentName}),'%') </select> 但是此时如果studentName为null,此语句很可能报错或查询结果为空。此时我们使用if动态sql语句先进行判断,如果值为null或等于空字符串,我们就不进行此条件的判断,增加灵活性。参数为实体类StudentEntity。将实体类中所有的属性均进行判断,如果不为空则执行判断条件。<!-- 2 if(判断参数) - 将实体类不为空的属性作为where条件 --> <select id="getStudentList_if" resultMap="resultMap_studentEntity" parameterType="liming.student.manager.data.model.StudentEntity"> SELECT ST.STUDENT_ID, ST.STUDENT_NAME, ST.STUDENT_SEX, ST.STUDENT_BIRTHDAY, ST.STUDENT_PHOTO, ST.CLASS_ID, ST.PLACE_ID FROM STUDENT_TBL ST WHERE <if test="studentName !=null "> ST.STUDENT_NAME LIKE CONCAT(CONCAT('%', #{studentName, jdbcType=VARCHAR}),'%') </if> <if test="studentSex != null and studentSex != '' "> AND ST.STUDENT_SEX = #{studentSex, jdbcType=INTEGER} </if> <if test="studentBirthday != null "> AND ST.STUDENT_BIRTHDAY = #{studentBirthday, jdbcType=DATE} </if> <if test="classId != null and classId!= '' "> AND ST.CLASS_ID = #{classId, jdbcType=VARCHAR} </if> <if test="classEntity != null and classEntity.classId !=null and classEntity.classId !=' ' "> AND ST.CLASS_ID = #{classEntity.classId, jdbcType=VARCHAR} </if> <if test="placeId != null and placeId != '' "> AND ST.PLACE_ID = #{placeId, jdbcType=VARCHAR} </if> <if test="placeEntity != null and placeEntity.placeId != null and placeEntity.placeId != '' "> AND ST.PLACE_ID = #{placeEntity.placeId, jdbcType=VARCHAR} </if> <if test="studentId != null and studentId != '' "> AND ST.STUDENT_ID = #{studentId, jdbcType=VARCHAR} </if> </select> 使用时比较灵活, new一个这样的实体类,我们需要限制那个条件,只需要附上相应的值就会where这个条件,相反不去赋值就可以不在where中判断。public void select_test_2_1() { StudentEntity entity = new StudentEntity(); entity.setStudentName(""); entity.setStudentSex(1); entity.setStudentBirthday(DateUtil.parse("1985-05-28")); entity.setClassId("20000001"); //entity.setPlaceId("70000001"); List<StudentEntity> list = this.dynamicSqlMapper.getStudentList_if(entity); for (StudentEntity e : list) { System.out.println(e.toString()); } }6、if + where 的条件判断当where中的条件使用的if标签较多时,这样的组合可能会导致错误。我们以在3.1中的查询语句为例子,当java代码按如下方法调用时:@Test public void select_test_2_1() { StudentEntity entity = new StudentEntity(); entity.setStudentName(null); entity.setStudentSex(1); List<StudentEntity> list = this.dynamicSqlMapper.getStudentList_if(entity); for (StudentEntity e : list) { System.out.println(e.toString()); } } 如果上面例子,参数studentName为null,将不会进行STUDENT\_NAME列的判断,则会直接导“WHERE AND”关键字多余的错误SQL。这时我们可以使用where动态语句来解决。这个“where”标签会知道如果它包含的标签中有返回值的话,它就插入一个‘where’。此外,如果标签返回的内容是以AND 或OR 开头的,则它会剔除掉。上面例子修改为:<!-- 3 select - where/if(判断参数) - 将实体类不为空的属性作为where条件 --> <select id="getStudentList_whereIf" resultMap="resultMap_studentEntity" parameterType="liming.student.manager.data.model.StudentEntity"> SELECT ST.STUDENT_ID, ST.STUDENT_NAME, ST.STUDENT_SEX, ST.STUDENT_BIRTHDAY, ST.STUDENT_PHOTO, ST.CLASS_ID, ST.PLACE_ID FROM STUDENT_TBL ST <where> <if test="studentName !=null "> ST.STUDENT_NAME LIKE CONCAT(CONCAT('%', #{studentName, jdbcType=VARCHAR}),'%') </if> <if test="studentSex != null and studentSex != '' "> AND ST.STUDENT_SEX = #{studentSex, jdbcType=INTEGER} </if> <if test="studentBirthday != null "> AND ST.STUDENT_BIRTHDAY = #{studentBirthday, jdbcType=DATE} </if> <if test="classId != null and classId!= '' "> AND ST.CLASS_ID = #{classId, jdbcType=VARCHAR} </if> <if test="classEntity != null and classEntity.classId !=null and classEntity.classId !=' ' "> AND ST.CLASS_ID = #{classEntity.classId, jdbcType=VARCHAR} </if> <if test="placeId != null and placeId != '' "> AND ST.PLACE_ID = #{placeId, jdbcType=VARCHAR} </if> <if test="placeEntity != null and placeEntity.placeId != null and placeEntity.placeId != '' "> AND ST.PLACE_ID = #{placeEntity.placeId, jdbcType=VARCHAR} </if> <if test="studentId != null and studentId != '' "> AND ST.STUDENT_ID = #{studentId, jdbcType=VARCHAR} </if> </where> </select> 7、if + set实现修改语句当update语句中没有使用if标签时,如果有一个参数为null,都会导致错误。当在update语句中使用if标签时,如果前面的if没有执行,则或导致逗号多余错误。使用set标签可以将动态的配置SET 关键字,和剔除追加到条件末尾的任何不相关的逗号。使用if+set标签修改后,如果某项为null则不进行更新,而是保持数据库原值。如下示例:<!-- 4 if/set(判断参数) - 将实体类不为空的属性更新 --> <update id="updateStudent_if_set" parameterType="liming.student.manager.data.model.StudentEntity"> UPDATE STUDENT_TBL <set> <if test="studentName != null and studentName != '' "> STUDENT_TBL.STUDENT_NAME = #{studentName}, </if> <if test="studentSex != null and studentSex != '' "> STUDENT_TBL.STUDENT_SEX = #{studentSex}, </if> <if test="studentBirthday != null "> STUDENT_TBL.STUDENT_BIRTHDAY = #{studentBirthday}, </if> <if test="studentPhoto != null "> STUDENT_TBL.STUDENT_PHOTO = #{studentPhoto, javaType=byte[], jdbcType=BLOB, typeHandler=org.apache.ibatis.type.BlobTypeHandler}, </if> <if test="classId != '' "> STUDENT_TBL.CLASS_ID = #{classId} </if> <if test="placeId != '' "> STUDENT_TBL.PLACE_ID = #{placeId} </if> </set> WHERE STUDENT_TBL.STUDENT_ID = #{studentId}; </update> 8、if + trim代替where/set标签trim是更灵活的去处多余关键字的标签,他可以实践where和set的效果。trim代替where<!-- 5.1if/trim代替where(判断参数) -将实体类不为空的属性作为where条件--> <select id="getStudentList_if_trim" resultMap="resultMap_studentEntity"> SELECT ST.STUDENT_ID, ST.STUDENT_NAME, ST.STUDENT_SEX, ST.STUDENT_BIRTHDAY, ST.STUDENT_PHOTO, ST.CLASS_ID, ST.PLACE_ID FROM STUDENT_TBL ST <trim prefix="WHERE" prefixOverrides="AND|OR"> <if test="studentName !=null "> ST.STUDENT_NAME LIKE CONCAT(CONCAT('%', #{studentName, jdbcType=VARCHAR}),'%') </if> <if test="studentSex != null and studentSex != '' "> AND ST.STUDENT_SEX = #{studentSex, jdbcType=INTEGER} </if> <if test="studentBirthday != null "> AND ST.STUDENT_BIRTHDAY = #{studentBirthday, jdbcType=DATE} </if> <if test="classId != null and classId!= '' "> AND ST.CLASS_ID = #{classId, jdbcType=VARCHAR} </if> <if test="classEntity != null and classEntity.classId !=null and classEntity.classId !=' ' "> AND ST.CLASS_ID = #{classEntity.classId, jdbcType=VARCHAR} </if> <if test="placeId != null and placeId != '' "> AND ST.PLACE_ID = #{placeId, jdbcType=VARCHAR} </if> <if test="placeEntity != null and placeEntity.placeId != null and placeEntity.placeId != '' "> AND ST.PLACE_ID = #{placeEntity.placeId, jdbcType=VARCHAR} </if> <if test="studentId != null and studentId != '' "> AND ST.STUDENT_ID = #{studentId, jdbcType=VARCHAR} </if> </trim> </select> trim代替set<!-- 5.2 if/trim代替set(判断参数) - 将实体类不为空的属性更新 --> <update id="updateStudent_if_trim" parameterType="liming.student.manager.data.model.StudentEntity"> UPDATE STUDENT_TBL <trim prefix="SET" suffixOverrides=","> <if test="studentName != null and studentName != '' "> STUDENT_TBL.STUDENT_NAME = #{studentName}, </if> <if test="studentSex != null and studentSex != '' "> STUDENT_TBL.STUDENT_SEX = #{studentSex}, </if> <if test="studentBirthday != null "> STUDENT_TBL.STUDENT_BIRTHDAY = #{studentBirthday}, </if> <if test="studentPhoto != null "> STUDENT_TBL.STUDENT_PHOTO = #{studentPhoto, javaType=byte[], jdbcType=BLOB, typeHandler=org.apache.ibatis.type.BlobTypeHandler}, </if> <if test="classId != '' "> STUDENT_TBL.CLASS_ID = #{classId}, </if> <if test="placeId != '' "> STUDENT_TBL.PLACE_ID = #{placeId} </if> </trim> WHERE STUDENT_TBL.STUDENT_ID = #{studentId} </update>9、foreach对于动态SQL 非常必须的,主是要迭代一个集合,通常是用于IN 条件。List 实例将使用“list”做为键,数组实例以“array” 做为键。foreach元素是非常强大的,它允许你指定一个集合,声明集合项和索引变量,它们可以用在元素体内。它也允许你指定开放和关闭的字符串,在迭代之间放置分隔符。这个元素是很智能的,它不会偶然地附加多余的分隔符。注意:你可以传递一个List实例或者数组作为参数对象传给MyBatis。当你这么做的时候,MyBatis会自动将它包装在一个Map中,用名称在作为键。List实例将会以“list”作为键,而数组实例将会以“array”作为键。这个部分是对关于XML配置文件和XML映射文件的而讨论的。下一部分将详细讨论Java API,所以你可以得到你已经创建的最有效的映射。参数为array示例的写法接口的方法声明:public List<StudentEntity> getStudentListByClassIds_foreach_array(String[] classIds); 动态SQL语句:<!-- 7.1 foreach(循环array参数) - 作为where中in的条件 --> <select id="getStudentListByClassIds_foreach_array" resultMap="resultMap_studentEntity"> SELECT ST.STUDENT_ID, ST.STUDENT_NAME, ST.STUDENT_SEX, ST.STUDENT_BIRTHDAY, ST.STUDENT_PHOTO, ST.CLASS_ID, ST.PLACE_ID FROM STUDENT_TBL ST WHERE ST.CLASS_ID IN <foreach collection="array" item="classIds" open="(" separator="," close=")"> #{classIds} </foreach> </select> 测试代码,查询学生中,在20000001、20000002这两个班级的学生:@Test public void test7_foreach() { String[] classIds = { "20000001", "20000002" }; List<StudentEntity> list = this.dynamicSqlMapper.getStudentListByClassIds_foreach_array(classIds); for (StudentEntity e : list) { System.out.println(e.toString()); } }参数为list示例的写法接口的方法声明:public List<StudentEntity> getStudentListByClassIds_foreach_list(List<String> classIdList); 动态SQL语句:<!-- 7.2 foreach(循环List<String>参数) - 作为where中in的条件 --> <select id="getStudentListByClassIds_foreach_list" resultMap="resultMap_studentEntity"> SELECT ST.STUDENT_ID, ST.STUDENT_NAME, ST.STUDENT_SEX, ST.STUDENT_BIRTHDAY, ST.STUDENT_PHOTO, ST.CLASS_ID, ST.PLACE_ID FROM STUDENT_TBL ST WHERE ST.CLASS_ID IN <foreach collection="list" item="classIdList" open="(" separator="," close=")"> #{classIdList} </foreach> </select>测试代码,查询学生中,在20000001、20000002这两个班级的学生:@Test public void test7_2_foreach() { ArrayList<String> classIdList = new ArrayList<String>(); classIdList.add("20000001"); classIdList.add("20000002"); List<StudentEntity> list = this.dynamicSqlMapper.getStudentListByClassIds_foreach_list(classIdList); for (StudentEntity e : list) { System.out.println(e.toString()); } } sql片段标签<sql>:通过该标签可定义能复用的sql语句片段,在执行sql语句标签中直接引用即可。这样既可以提高编码效率,还能有效简化代码,提高可读性需要配置的属性:id="" >>>表示需要改sql语句片段的唯一标识引用:通过<include refid="" />标签引用,refid="" 中的值指向需要引用的<sql>中的id=“”属性<!--定义sql片段--> <sql id="orderAndItem"> o.order_id,o.cid,o.address,o.create_date,o.orderitem_id,i.orderitem_id,i.product_id,i.count </sql> <select id="findOrderAndItemsByOid" parameterType="java.lang.String" resultMap="BaseResultMap"> select <!--引用sql片段--> <include refid="orderAndItem" /> from ordertable o join orderitem i on o.orderitem_id = i.orderitem_id where o.order_id = #{orderId} </select>
-
Springboot redis 消息订阅发布 /** * 事件类型 */ public enum EventType { ORDER_CREATE("order_create","订单创建"), ORDER_CANCEL("order_cancel","订单取消"), ; private String type; private String name; EventType(String type, String name) { this.type = type; this.name = name; } public String getType() { return type; } public void setType(String type) { this.type = type; } public String getName() { return name; } public void setName(String name) { this.name = name; } }/** * 事件数据 */ @Data @Builder public class EventData implements Serializable { private EventType eventType; private Object data; // 默认构造函数 public EventData() { } @JsonCreator public EventData(@JsonProperty("eventType") EventType eventType, @JsonProperty("data") Object data) { this.eventType = eventType; this.data = data; } }/** * 事件消费者 */ @Slf4j @Component public class EventConsumer { private final Map<String, List<Consumer<EventData>>> eventContent = new HashMap<>(); /** * 添加消费者 * * @param eventType 事件类型 * @param consumer 消费者 */ public void addConsumer(EventType eventType, Consumer<EventData> consumer) { log.info("添加消费者:{}", eventType.getType()); eventContent.computeIfAbsent(eventType.getType(), k -> new ArrayList<>()).add(consumer); } /** * 获取消费者列表 * * @param eventType 事件类型 * @return 消费者列表 */ public List<Consumer<EventData>> getConsumers(EventType eventType) { return eventContent.getOrDefault(eventType.getType(), Collections.emptyList()); } }/** * 订阅发布 */ @Component @Slf4j public class PublishService { private static final long EXPIRE_TIME = 24 * 60 * 60; @Resource StringRedisTemplate stringRedisTemplate; @Resource private RedisService redisService; private final static String MALL_MESSAGE_PREFIX = "mall:message:"; /** * 发送消息 */ public void publish(EventData eventData) { log.info("====发布Redis订阅:{}====", JSON.toJSONString(eventData)); String redisKey = MALL_MESSAGE_PREFIX + IdUtil.fastSimpleUUID(); redisService.set(redisKey, eventData, EXPIRE_TIME); stringRedisTemplate.convertAndSend(eventData.getEventType().getType(), redisKey); } }@Configuration public class RedisListenerConfig { @Resource EventConsumer eventConsumer; @Bean public RedisMessageListenerContainer container(RedisConnectionFactory connectionFactory, MessageListenerAdapter listenerAdapter) { RedisMessageListenerContainer container = new RedisMessageListenerContainer(); container.setConnectionFactory(connectionFactory); for (EventType value : EventType.values()) { container.addMessageListener(listenerAdapter, new PatternTopic(value.getType())); } return container; } @Bean public MessageListenerAdapter listenerAdapter(SubscribeListener subscribeListener) { return new MessageListenerAdapter(subscribeListener); } // bean 实例化后添加consumer @PostConstruct public void init() { // 添加消费者 eventConsumer.addConsumer(EventType.ORDER_CREATE, eventData -> { System.out.println("Handling order creation: " + eventData.getData()); }); eventConsumer.addConsumer(EventType.ORDER_CANCEL, eventData -> { System.out.println("Handling order cancellation: " + eventData.getData()); }); } } @Component @Slf4j public class SubscribeListener implements MessageListener { @Resource private EventConsumer eventConsumer; @Resource private StringRedisTemplate stringRedisTemplate; @Resource private RedisService redisService; @Override public void onMessage(Message message, byte[] pattern) { try { RedisSerializer<String> stringSerializer = stringRedisTemplate.getStringSerializer(); String redisKey = stringSerializer.deserialize(message.getBody()); if (redisKey != null) { String messageData = JSON.toJSONString(redisService.get(redisKey)); EventData eventData = JSON.parseObject(messageData, EventData.class); log.info("====接收Redis订阅:{}====", JSON.toJSONString(eventData)); if (eventData != null) { List<Consumer<EventData>> consumers = eventConsumer.getConsumers(eventData.getEventType()); consumers.forEach(consumer -> consumer.accept(eventData)); } redisService.del(redisKey); } } catch (Exception e) { log.warn("处理订阅消息时出错: ", e); } } }
-
Mybatis plus 封装前后端查询的基础条件 @Data @ToString @Builder public class MallQueryDTO implements Serializable { public static final long serialVersionUID = 5510022355351221662L; public Integer pageNo; public Integer pageSize; public List<PairOfQueryDTO> filter; public List<PairOfSortDTO> sort; }@Data @Builder public class PairOfQueryDTO implements Serializable { private static final long serialVersionUID = -8952875265623011362L; private String key; private String value; // 查询方式 eq/gt/ge/lt/le/in/like/isNotNUll private String by; }@Data @Builder public class PairOfSortDTO implements Serializable { private static final long serialVersionUID = -3413644584659764949L; private String key; // 排序方式 "DESC/ASC" private String order; }@Slf4j public class MallQueryWrapper<T> { private T entity; private MallQueryDTO mallQueryDTO; /*** * 查询条件 * eg = * ge >= * gt > * le <= * lt < * in in * like like * ne != */ private static final String FILTER_EQ = "eq"; private static final String FILTER_GE = "ge"; private static final String FILTER_GT = "gt"; private static final String FILTER_LE = "le"; private static final String FILTER_LT = "lt"; private static final String FILTER_IN = "in"; private static final String FILTER_LIKE = "like"; private static final String FILTER_NE = "ne"; private static final String FILTER_ISNOTNULL = "isNotNull"; private static final String SORT_ASC = "ASC"; private static final String SORT_DESC = "DESC"; private static final int DEFAULT_PAGE_SIZE = 10; private static final int DEFAULT_PAGE_NO = 1; /*** * @param entity 数据库实体, 设置对应参数值 等同于 name = value , 对象为null时,不生效 * @param mallQueryDTO 通用查询参数 */ public MallQueryWrapper(T entity, MallQueryDTO mallQueryDTO) { this.entity = entity; this.mallQueryDTO = mallQueryDTO; } public Page<T> getPageInstance() { if (null == mallQueryDTO) { mallQueryDTO = MallQueryDTO.builder().build(); } log.info("QueryWrapper queryDTO:{}, entity:{}", mallQueryDTO, entity); // current 从0开始的 int current = mallQueryDTO.getPageNo() == null || mallQueryDTO.getPageNo() < 1 ? DEFAULT_PAGE_NO : mallQueryDTO.getPageNo(); int size = mallQueryDTO.getPageSize() == null || mallQueryDTO.getPageNo() < 1 ? DEFAULT_PAGE_SIZE : mallQueryDTO.getPageSize(); return new Page<>(current, size); } public QueryWrapper<T> getWrapperInstance() { QueryWrapper<T> entityWrapper = new QueryWrapper<T>(); if (Objects.nonNull(entity)) { entityWrapper.setEntity(entity); } // 转换查询条件 if (!CollectionUtils.isEmpty(mallQueryDTO.getFilter())) { mallQueryDTO.getFilter().forEach(filter -> { if (FILTER_EQ.equalsIgnoreCase(filter.getBy())) { entityWrapper.eq(filter.getKey(), filter.getValue()); } else if (FILTER_GE.equalsIgnoreCase(filter.getBy())) { entityWrapper.ge(filter.getKey(), filter.getValue()); } else if (FILTER_GT.equalsIgnoreCase(filter.getBy())) { entityWrapper.gt(filter.getKey(), filter.getValue()); } else if (FILTER_LE.equalsIgnoreCase(filter.getBy())) { entityWrapper.le(filter.getKey(), filter.getValue()); } else if (FILTER_LT.equalsIgnoreCase(filter.getBy())) { entityWrapper.lt(filter.getKey(), filter.getValue()); } else if (FILTER_IN.equalsIgnoreCase(filter.getBy())) { entityWrapper.in(filter.getKey(), filter.getValue()); } else if (FILTER_LIKE.equalsIgnoreCase(filter.getBy())) { entityWrapper.like(filter.getKey(), filter.getValue()); } else if (FILTER_NE.equalsIgnoreCase(filter.getBy())) { entityWrapper.ne(filter.getKey(), filter.getValue()); } else if (FILTER_ISNOTNULL.equalsIgnoreCase(filter.getBy())) { entityWrapper.isNotNull(filter.getKey()); } }); } // 转换排序字段 if (!CollectionUtils.isEmpty(mallQueryDTO.getSort())) { mallQueryDTO.getSort().forEach(sort -> { if (SORT_ASC.equalsIgnoreCase(sort.getOrder())) { entityWrapper.orderByAsc(sort.getKey()); } if (SORT_DESC.equalsIgnoreCase(sort.getOrder())) { entityWrapper.orderByDesc(sort.getKey()); } }); } return entityWrapper; } } // 示例一:分页查询 @Override public PageDTO<PaidRedpackVO> list(QueryDTO queryDTO) { PaidRedpack pr = PaidRedpack.builder().build(); QueryWrapper<PaidRedpack> queryWrapper = new QueryWrapper<>(pr, queryDTO); Page<PaidRedpack> page = paidRedpackDao.selectPage(queryWrapper.getPageInstance(), queryWrapper.getWrapperInstance()); }
-
Spring中11个最常用的扩展点 前言在使用spring的过程中,我们有没有发现它的扩展能力很强呢? 由于这个优势的存在,使得spring具有很强的包容性,所以很多第三方应用或者框架可以很容易的投入到spring的怀抱中。今天我们主要来学习Spring中很常用的11个扩展点,你用过几个呢?1. 类型转换器如果接口中接收参数的实体对象中,有一个字段类型为Date,但实际传递的参数是字符串类型:2022-12-15 10:20:15,该如何处理?Spring提供了一个扩展点,类型转换器Type Converter,具体分为3类:Converter<S,T>: 将类型 S 的对象转换为类型 T 的对象ConverterFactory<S, R>: 将 S 类型对象转换为 R 类型或其子类对象GenericConverter:它支持多种源和目标类型的转换,还提供了源和目标类型的上下文。 此上下文允许您根据注释或属性信息执行类型转换。还是不明白的话,我们举个例子吧。定义一个用户对象@Data public class User { private Long id; private String name; private Date registerDate; }实现Converter接口public class DateConverter implements Converter<String, Date> { private SimpleDateFormat simpleDateFormat = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss"); @Override public Date convert(String source) { if (source != null && !"".equals(source)) { try { simpleDateFormat.parse(source); } catch (ParseException e) { e.printStackTrace(); } } return null; } }将新定义的类型转换器注入到Spring容器中@Configuration public class WebConfig extends WebMvcConfigurerAdapter { @Override public void addFormatters(FormatterRegistry registry) { registry.addConverter(new DateConverter()); } }调用接口测试@RequestMapping("/user") @RestController public class UserController { @RequestMapping("/save") public String save(@RequestBody User user) { return "success"; } }请求接口时,前端传入的日期字符串,会自动转换成Date类型。2. 获取容器Bean在我们日常开发中,经常需要从Spring容器中获取bean,但是你知道如何获取Spring容器对象吗?2.1 BeanFactoryAware@Service public class PersonService implements BeanFactoryAware { private BeanFactory beanFactory; @Override public void setBeanFactory(BeanFactory beanFactory) throws BeansException { this.beanFactory = beanFactory; } public void add() { Person person = (Person) beanFactory.getBean("person"); } }实现BeanFactoryAware接口,然后重写setBeanFactory方法,可以从方法中获取spring容器对象。2.2 ApplicationContextAware@Service public class PersonService2 implements ApplicationContextAware { private ApplicationContext applicationContext; @Override public void setApplicationContext(ApplicationContext applicationContext) throws BeansException { this.applicationContext = applicationContext; } public void add() { Person person = (Person) applicationContext.getBean("person"); } }实现ApplicationContextAware接口,然后重写setApplicationContext方法,也可以通过该方法获取spring容器对象。2.3 ApplicationListener@Service public class PersonService3 implements ApplicationListener<ContextRefreshedEvent> { private ApplicationContext applicationContext; @Override public void onApplicationEvent(ContextRefreshedEvent event) { applicationContext = event.getApplicationContext(); } public void add() { Person person = (Person) applicationContext.getBean("person"); } }3. 全局异常处理以往我们在开发界面的时候,如果出现异常,要给用户更友好的提示,例如:@RequestMapping("/test") @RestController public class TestController { @GetMapping("/add") public String add() { int a = 10 / 0; return "su"; } }如果不对请求添加接口结果做任何处理,会直接报错:用户可以直接看到错误信息吗?这种交互给用户带来的体验非常差。 为了解决这个问题,我们通常在接口中捕获异常:@GetMapping("/add") public String add() { String result = "success"; try { int a = 10 / 0; } catch (Exception e) { result = "error"; } return result; }界面修改后,出现异常时会提示:“数据异常”,更加人性化。看起来不错,但是有一个问题。如果只是一个接口还好,但是如果项目中有成百上千个接口,还得加异常捕获代码吗?答案是否定的,这就是全局异常处理派上用场的地方:RestControllerAdvice。@RestControllerAdvice public class GlobalExceptionHandler { @ExceptionHandler(Exception.class) public String handleException(Exception e) { if (e instanceof ArithmeticException) { return "data error"; } if (e instanceof Exception) { return "service error"; } retur null; } }方法中处理异常只需要handleException,在业务接口中就可以安心使用,不再需要捕获异常(统一有人处理)。4. 自定义拦截器Spring MVC拦截器,它可以获得HttpServletRequest和HttpServletResponse等web对象实例。Spring MVC拦截器的顶层接口是HandlerInterceptor,它包含三个方法:preHandle 在目标方法执行之前执行执行目标方法后执行的postHandleafterCompletion 在请求完成时执行为了方便,我们一般继承HandlerInterceptorAdapter,它实现了HandlerInterceptor。如果有授权鉴权、日志、统计等场景,可以使用该拦截器,我们来演示下吧。写一个类继承HandlerInterceptorAdapter:public class AuthInterceptor extends HandlerInterceptorAdapter { @Override public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) throws Exception { String requestUrl = request.getRequestURI(); if (checkAuth(requestUrl)) { return true; } return false; } private boolean checkAuth(String requestUrl) { return true; } }将拦截器注册到spring容器中@Configuration public class WebAuthConfig extends WebMvcConfigurerAdapter { @Bean public AuthInterceptor getAuthInterceptor() { return new AuthInterceptor(); } @Override public void addInterceptors(InterceptorRegistry registry) { registry.addInterceptor(new AuthInterceptor()); } }Spring MVC在请求接口时可以自动拦截接口,并通过拦截器验证权限。5. 导入配置有时我们需要在某个配置类中引入其他的类,引入的类也加入到Spring容器中。 这时候可以使用注解@Import来完成这个功能。如果你查看它的源代码,你会发现导入的类支持三种不同的类型。但是我觉得最好把普通类的配置类和@Configuration注解分开解释,所以列出了四种不同的类型:5.1 通用类这种引入方式是最简单的,引入的类会被实例化为一个bean对象。public class A { } @Import(A.class) @Configuration public class TestConfiguration { }通过@Import注解引入类A,spring可以自动实例化A对象,然后在需要使用的地方通过注解@Autowired注入:@Autowired private A a;5.2 配置类这种引入方式是最复杂的,因为@Configuration支持还支持多种组合注解,比如:@Import @ImportResource @PropertySource public class A { } public class B { } @Import(B.class) @Configuration public class AConfiguration { @Bean public A a() { return new A(); } } @Import(AConfiguration.class) @Configuration public class TestConfiguration { }@Configuration注解的配置类通过@Import注解导入,配置类@Import、@ImportResource相关注解引入的类会一次性全部递归引入@PropertySource所在的属性。5.3 ImportSelector该导入方法需要实现ImportSelector接口public class AImportSelector implements ImportSelector { private static final String CLASS_NAME = "com.sue.cache.service.test13.A"; public String[] selectImports(AnnotationMetadata importingClassMetadata) { return new String[]{CLASS_NAME}; } } @Import(AImportSelector.class) @Configuration public class TestConfiguration { }这种方法的好处是selectImports方法返回的是一个数组,也就是说可以同时引入多个类,非常方便。5.4 ImportBeanDefinitionRegistrar该导入方法需要实现ImportBeanDefinitionRegistrar接口:public class AImportBeanDefinitionRegistrar implements ImportBeanDefinitionRegistrar { @Override public void registerBeanDefinitions(AnnotationMetadata importingClassMetadata, BeanDefinitionRegistry registry) { RootBeanDefinition rootBeanDefinition = new RootBeanDefinition(A.class); registry.registerBeanDefinition("a", rootBeanDefinition); } } @Import(AImportBeanDefinitionRegistrar.class) @Configuration public class TestConfiguration { }这种方法是最灵活的。 容器注册对象可以在registerBeanDefinitions方法中获取,可以手动创建BeanDefinition注册到BeanDefinitionRegistry种。6. 当工程启动时有时候我们需要在项目启动的时候自定义一些额外的功能,比如加载一些系统参数,完成初始化,预热本地缓存等。 我们应该做什么?好消息是 SpringBoot 提供了:CommandLineRunnerApplicationRunner这两个接口帮助我们实现了上面的需求。它们的用法很简单,以ApplicationRunner接口为例:@Component public class TestRunner implements ApplicationRunner { @Autowired private LoadDataService loadDataService; public void run(ApplicationArguments args) throws Exception { loadDataService.load(); } }实现ApplicationRunner接口,重写run方法,在该方法中实现您的自定义需求。如果项目中有多个类实现了ApplicationRunner接口,如何指定它们的执行顺序?答案是使用@Order(n)注解,n的值越小越早执行。 当然,顺序也可以通过@Priority注解来指定。7. 修改BeanDefinition在实例化Bean对象之前,Spring IOC需要读取Bean的相关属性,保存在BeanDefinition对象中,然后通过BeanDefinition对象实例化Bean对象。如果要修改BeanDefinition对象中的属性怎么办?答案:我们可以实现 BeanFactoryPostProcessor 接口。@Component public class MyBeanFactoryPostProcessor implements BeanFactoryPostProcessor { @Override public void postProcessBeanFactory(ConfigurableListableBeanFactory configurableListableBeanFactory) throws BeansException { DefaultListableBeanFactory defaultListableBeanFactory = (DefaultListableBeanFactory) configurableListableBeanFactory; BeanDefinitionBuilder beanDefinitionBuilder = BeanDefinitionBuilder.genericBeanDefinition(User.class); beanDefinitionBuilder.addPropertyValue("id", 123); beanDefinitionBuilder.addPropertyValue("name", "Tom"); defaultListableBeanFactory.registerBeanDefinition("user", beanDefinitionBuilder.getBeanDefinition()); } }在postProcessBeanFactory方法中,可以获取BeanDefinition的相关对象,修改对象的属性。8. 初始化 Bean 前和后有时,您想在 bean 初始化前后实现一些您自己的逻辑。这时候就可以实现:BeanPostProcessor接口。该接口目前有两个方法:postProcessBeforeInitialization:应该在初始化方法之前调用。postProcessAfterInitialization:此方法在初始化方法之后调用。@Component public class MyBeanPostProcessor implements BeanPostProcessor { @Override public Object postProcessAfterInitialization(Object bean, String beanName) throws BeansException { if (bean instanceof User) { ((User) bean).setUserName("Tom"); } return bean; } }我们经常使用的@Autowired、@Value、@Resource、@PostConstruct等注解都是通过AutowiredAnnotationBeanPostProcessor和CommonAnnotationBeanPostProcessor来实现的。9. 初始化方法目前在Spring中初始化bean的方式有很多种:使用@PostConstruct注解实现InitializingBean接口9.1 使用@PostConstruct@Service public class AService { @PostConstruct public void init() { System.out.println("===init==="); } }为需要初始化的方法添加注解@PostConstruct,使其在Bean初始化时执行。9.2 实现初始化接口InitializingBean@Service public class BService implements InitializingBean { @Override public void afterPropertiesSet() throws Exception { System.out.println("===init==="); } }实现InitializingBean接口,重写afterPropertiesSet方法,在该方法中可以完成初始化功能。10. 关闭Spring容器前有时候,我们需要在关闭spring容器之前做一些额外的工作,比如关闭资源文件。此时你可以实现 DisposableBean 接口并重写它的 destroy 方法。@Service public class DService implements InitializingBean, DisposableBean { @Override public void destroy() throws Exception { System.out.println("DisposableBean destroy"); } @Override public void afterPropertiesSet() throws Exception { System.out.println("InitializingBean afterPropertiesSet"); } }这样,在spring容器销毁之前,会调用destroy方法做一些额外的工作。通常我们会同时实现InitializingBean和DisposableBean接口,重写初始化方法和销毁方法。11. 自定义Bean的scope我们都知道spring core默认只支持两种Scope:Singleton单例,从spring容器中获取的每一个bean都是同一个对象。prototype多实例,每次从spring容器中获取的bean都是不同的对象。Spring Web 再次扩展了 Scope,添加RequestScope:同一个请求中从spring容器中获取的bean都是同一个对象。SessionScope:同一个session从spring容器中获取的bean都是同一个对象。尽管如此,有些场景还是不符合我们的要求。比如我们在同一个线程中要从spring容器中获取的bean都是同一个对象,怎么办?答案:这需要一个自定义范围。实现 Scope 接口public class ThreadLocalScope implements Scope { private static final ThreadLocal THREAD_LOCAL_SCOPE = new ThreadLocal(); @Override public Object get(String name, ObjectFactory<?> objectFactory) { Object value = THREAD_LOCAL_SCOPE.get(); if (value != null) { return value; } Object object = objectFactory.getObject(); THREAD_LOCAL_SCOPE.set(object); return object; } @Override public Object remove(String name) { THREAD_LOCAL_SCOPE.remove(); return null; } @Override public void registerDestructionCallback(String name, Runnable callback) { } @Override public Object resolveContextualObject(String key) { return null; } @Override public String getConversationId() { return null; } }将新定义的Scope注入到Spring容器中@Component public class ThreadLocalBeanFactoryPostProcessor implements BeanFactoryPostProcessor { @Override public void postProcessBeanFactory(ConfigurableListableBeanFactory beanFactory) throws BeansException { beanFactory.registerScope("threadLocalScope", new ThreadLocalScope()); } }使用新定义的Scope@Scope("threadLocalScope") @Service public class CService { public void add() { } }总结本文总结了Spring中很常用的11个扩展点,可以在Bean创建、初始化到销毁各个阶段注入自己想要的逻辑,也有Spring MVC相关的拦截器等扩展点,希望对大家有帮助。
-
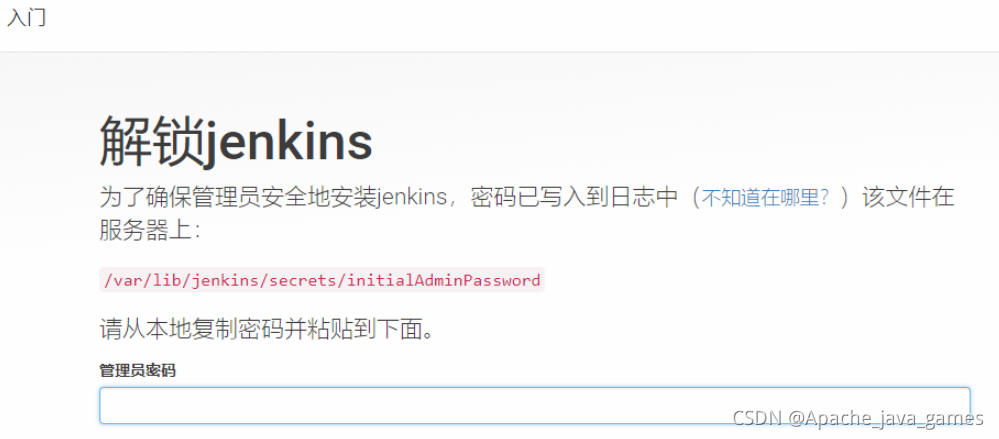
Jenkins+Docker 一键自动化部署 SpringBoot 项目 {mtitle title="安装Jenkins"/}1.安装Jenkinsdocker 安装一切都是那么简单,注意检查8080是否已经占用!如果占用修改端口docker run --name jenkins -u root --rm -d -p 8080:8080 -p 50000:50000 -v /var/jenkins_home:/var/jenkins_home -v /var/run/docker.sock:/var/run/docker.sock jenkinsci/blueocean如果没改端口号的话,安装完成后访问地址-> http://{部署Jenkins所在服务IP}:8080,此处会有几分钟的等待时间。{mtitle title="初始化Jenkins"/}解锁Jenkins进入Jenkins容器:docker exec -it {Jenkins容器名} bash例如 docker exec -it jenkins bash查看密码:cat /var/lib/jenkins/secrets/initialAdminPassword复制密码到输入框里面安装插件选择第一个安装推荐的插件创建管理员用户此账户一定要记住哦{mtitle title="系统配置"/}安装需要插件进入【首页】–【系统管理】–【插件管理】–【可选插件】搜索以下需要安装的插件,点击安装即可。安装Maven Integration安装Publish Over SSH(如果不需要远程推送,不用安装)如果使用Gitee 码云,安装插件Gitee(Git自带不用安装)配置Maven进入【首页】–【系统管理】–【全局配置】,拉到最下面maven–maven安装{mtitle title="创建任务"/}新建任务点击【新建任务】,输入任务名称,点击构建一个自由风格的软件项目源码管理点击【源码管理】–【Git】,输入仓库地址,添加凭证,选择好凭证即可。构建触发器点击【构建触发器】–【构建】–【增加构建步骤】–【调用顶层Maven目标】–【填写配置】–【保存】此处命令只是install,看是否能生成jar包clean install -Dmaven.test.skip=true{mtitle title="运行项目"/}因为我们项目和jenkins在同一台服务器,所以我们用shell脚本运行项目,原理既是通过dockerfile 打包镜像,然后docker运行即可。Dockerfile在springboot项目根目录新建一个名为Dockerfile的文件,注意没有后缀名,其内容如下:(大致就是使用jdk8,把jar包添加到docker然后运行prd配置文件。详细可以查看其他教程)FROM jdk:8 VOLUME /tmp ADD target/zx-order-0.0.1-SNAPSHOT.jar app.jar EXPOSE 8888 ENTRYPOINT ["Bash","-DBash.security.egd=file:/dev/./urandom","-jar","/app.jar","--spring.profiles.active=prd"]修改jenkins任务配置配置如下:-t:指定新镜像名.:表示Dockfile在当前路径cd /var/jenkins_home/workspace/zx-order-api docker stop zx-order || true docker rm zx-order || true docker rmi zx-order || true docker build -t zx-order . docker run -d -p 8888:8888 --name zx-order zx-order:latest备注:上图用了docker logs -f 是为了方便看日志,真实不要用,因为会一直等待日志,构建任务会失败加|| true 是如果命令执行失败也会继续实行,为了防止第一次没有该镜像报错构建验证docker ps 查看是否有自己的容器docker logs 自己的容器名 查看日志是否正确浏览器访问项目试一试
-
瞧瞧人家写的API接口代码,那叫一个优雅! {mtitle title="前言"/} 在实际工作中,我们需要经常跟第三方平台打交道,可能会对接第三方平台API接口,或者提供API接口给第三方平台调用。那么问题来了,如何设计一个优雅的API接口,能够满足:安全性、可重复调用、稳定性、好定位问题等多方面需求? 今天跟大家一起聊聊设计API接口时,需要注意的一些地方,希望对你会有所帮助。1. 签名 为了防止API接口中的数据被篡改,很多时候我们需要对API接口做签名。接口请求方将请求参数 + 时间戳 + 密钥拼接成一个字符串,然后通过md5等hash算法,生成一个前面sign。然后在请求参数或者请求头中,增加sign参数,传递给API接口。API接口的网关服务,获取到该sign值,然后用相同的请求参数 + 时间戳 + 密钥拼接成一个字符串,用相同的m5算法生成另外一个sign,对比两个sign值是否相等。如果两个sign相等,则认为是有效请求,API接口的网关服务会将给请求转发给相应的业务系统。如果两个sign不相等,则API接口的网关服务会直接返回签名错误。 问题来了:签名中为什么要加时间戳? 答:为了安全性考虑,防止同一次请求被反复利用,增加了密钥没破解的可能性,我们必须要对每次请求都设置一个合理的过期时间,比如:15分钟。这样一次请求,在15分钟之内是有效的,超过15分钟,API接口的网关服务会返回超过有效期的异常提示。目前生成签名中的密钥有两种形式:一种是双方约定一个固定值privateKey。另一种是API接口提供方给出AK/SK两个值,双方约定用SK作为签名中的密钥。AK接口调用方作为header中的accessKey传递给API接口提供方,这样API接口提供方可以根据AK获取到SK,而生成新的sgin。2. 加密 有些时候,我们的API接口直接传递的非常重要的数据,比如:用户的银行卡号、转账金额、用户身份证等,如果将这些参数,直接明文,暴露到公网上是非常危险的事情。由此,我们需要对数据进行加密。目前使用比较多的是用BASE64加解密。我们可以将所有的数据,安装一定的规律拼接成一个大的字符串,然后在加一个密钥,拼接到一起。然后使用JDK1.8之后的Base64工具类处理,效果如下: 【加密前的数据】www.baidu.com【加密后的数据】d3d3LmJhaWR1LmNvbQ==为了安全性,使用Base64可以加密多次。 API接口的调用方在传递参数时,body中只有一个参数data,它就是base64之后的加密数据。API接口的网关服务,在接收到data数据后,根据双方事先预定的密钥、加密算法、加密次数等,进行解密,并且反序列化出参数数据。3. ip白名单 为了进一步加强API接口的安全性,防止接口的签名或者加密被破解了,攻击者可以在自己的服务器上请求该接口。需求限制请求ip,增加ip白名单。只有在白名单中的ip地址,才能成功请求API接口,否则直接返回无访问权限。ip白名单也可以加在API网关服务上。但也要防止公司的内部应用服务器被攻破,这种情况也可以从内部服务器上发起API接口的请求。时候就需要增加web防火墙了,比如:ModSecurity等。4. 限流 如果你的API接口被第三方平台调用了,这就意味着着,调用频率是没法控制的。第三方平台调用你的API接口时,如果并发量一下子太高,可能会导致你的API服务不可用,接口直接挂掉。由此,必须要对API接口做限流。限流方法有三种: 对请求ip做限流:比如同一个ip,在一分钟内,对API接口总的请求次数,不能超过10000次。对请求接口做限流:比如同一个ip,在一分钟内,对指定的API接口,请求次数不能超过2000次。对请求用户做限流:比如同一个AK/SK用户,在一分钟内,对API接口总的请求次数,不能超过10000次。我们在实际工作中,可以通过nginx,redis或者gateway实现限流的功能。5. 参数校验 我们需要对API接口做参数校验,比如:校验必填字段是否为空,校验字段类型,校验字段长度,校验枚举值等等。这样做可以拦截一些无效的请求。比如在新增数据时,字段长度超过了数据字段的最大长度,数据库会直接报错。但这种异常的请求,我们完全可以在API接口的前期进行识别,没有必要走到数据库保存数据那一步,浪费系统资源。有些金额字段,本来是正数,但如果用户传入了负数,万一接口没做校验,可能会导致一些没必要的损失。还有些状态字段,如果不做校验,用户如果传入了系统中不存在的枚举值,就会导致保存的数据异常。由此可见,做参数校验是非常有必要的。在Java中校验数据使用最多的是hiberate的Validator框架,它里面包含了@Null、@NotEmpty、@Size、@Max、@Min等注解。用它们校验数据非常方便。 当然有些日期字段和枚举字段,可能需要通过自定义注解的方式实现参数校验。6. 统一返回值我之前调用过别人的API接口,正常返回数据是一种json格式,比如:{ "code":0, "message":null, "data":[{"id":123,"name":"abc"}] }签名错误返回的json格式:{ "code":1001, "message":"签名错误", "data":null }没有数据权限返回的json格式:{ "rt":10, "errorMgt":"没有权限", "result":null } 这种是比较坑的做法,返回值中有多种不同格式的返回数据,这样会导致对接方很难理解。出现这种情况,可能是API网关定义了一直返回值结构,业务系统定义了另外一种返回值结构。如果是网关异常,则返回网关定义的返回值结构,如果是业务系统异常,则返回业务系统的返回值结构。但这样会导致API接口出现不同的异常时,返回不同的返回值结构,非常不利于接口的维护。其实这个问题我们可以在设计API网关时解决。业务系统在出现异常时,抛出业务异常的RuntimeException,其中有个message字段定义异常信息。所有的API接口都必须经过API网关,API网关捕获该业务异常,然后转换成统一的异常结构返回,这样能统一返回值结构。7. 统一封装异常 我们的API接口需要对异常进行统一处理。不知道你有没有遇到过这种场景:有时候在API接口中,需要访问数据库,但表不存在,或者sql语句异常,就会直接把sql信息在API接口中直接返回。返回值中包含了异常堆栈信息、数据库信息、错误代码和行数等信息。如果直接把这些内容暴露给第三方平台,是很危险的事情。有些不法分子,利用接口返回值中的这些信息,有可能会进行sql注入或者直接脱库,而对我们系统造成一定的损失。因此非常有必要对API接口中的异常做统一处理,把异常转换成这样:{ "code":500, "message":"服务器内部错误", "data":null } 返回码code是500,返回信息message是服务器内部异常。这样第三方平台就知道是API接口出现了内部问题,但不知道具体原因,他们可以找我们排查问题。我们可以在内部的日志文件中,把堆栈信息、数据库信息、错误代码行数等信息,打印出来。我们可以在gateway中对异常进行拦截,做统一封装,然后给第三方平台的是处理后没有敏感信息的错误信息。8. 请求日志 在第三方平台请求你的API接口时,接口的请求日志非常重要,通过它可以快速的分析和定位问题。我们需要把API接口的请求url、请求参数、请求头、请求方式、响应数据和响应时间等,记录到日志文件中。最好有traceId,可以通过它串联整个请求的日志,过滤多余的日志。当然有些时候,请求日志不光是你们公司开发人员需要查看,第三方平台的用户也需要能查看接口的请求日志。这时就需要把日志落地到数据库,比如:mongodb或者elastic search,然后做一个UI页面,给第三方平台的用户开通查看权限。这样他们就能在外网查看请求日志了,他们自己也能定位一部分问题。9. 幂等设计 第三方平台极有可能在极短的时间内,请求我们接口多次,比如:在1秒内请求两次。有可能是他们业务系统有bug,或者在做接口调用失败重试,因此我们的API接口需要做幂等设计。也就是说要支持在极短的时间内,第三方平台用相同的参数请求API接口多次,第一次请求数据库会新增数据,但第二次请求以后就不会新增数据,但也会返回成功。这样做的目的是不会产生错误数据。我们在日常工作中,可以通过在数据库中增加唯一索引,或者在redis保存requestId和请求参来保证接口幂等性。对接口幂等性感兴趣的小伙伴,可以看看我的另一篇文章《高并发下如何保证接口的幂等性?》,里面有非常详细的介绍。10. 限制记录条数 对于对我提供的批量接口,一定要限制请求的记录条数。如果请求的数据太多,很容易造成API接口超时等问题,让API接口变得不稳定。通常情况下,建议一次请求中的参数,最多支持传入500条记录。如果用户传入多余500条记录,则接口直接给出提示。建议这个参数做成可配置的,并且要事先跟第三方平台协商好,避免上线后产生不必要的问题。11. 压测 上线前我们务必要对API接口做一下压力测试,知道各个接口的qps情况。以便于我们能够更好的预估,需要部署多少服务器节点,对于API接口的稳定性至关重要。之前虽说对API接口做了限流,但是实际上API接口是否能够达到限制的阀值,这是一个问号,如果不做压力测试,是有很大风险的。比如:你API接口限流1秒只允许50次请求,但实际API接口只能处理30次请求,这样你的API接口也会处理不过来。我们在工作中可以用jmeter或者apache benc对API接口做压力测试。12. 异步处理 一般的API接口的逻辑都是同步处理的,请求完之后立刻返回结果。但有时候,我们的API接口里面的业务逻辑非常复杂,特别是有些批量接口,如果同步处理业务,耗时会非常长。这种情况下,为了提升API接口的性能,我们可以改成异步处理。在API接口中可以发送一条mq消息,然后直接返回成功。之后,有个专门的mq消费者去异步消费该消息,做业务逻辑处理。直接异步处理的接口,第三方平台有两种方式获取到。第一种方式是:我们回调第三方平台的接口,告知他们API接口的处理结果,很多支付接口就是这么玩的。第二种方式是:第三方平台通过轮询调用我们另外一个查询状态的API接口,每隔一段时间查询一次状态,传入的参数是之前的那个API接口中的id集合。13. 数据脱敏 有时候第三方平台调用我们API接口时,获取的数据中有一部分是敏感数据,比如:用户手机号、银行卡号等等。这样信息如果通过API接口直接保留到外网,是非常不安全的,很容易造成用户隐私数据泄露的问题。这就需要对部分数据做数据脱敏了。我们可以在返回的数据中,部分内容用星号代替。已用户手机号为例:182**887。这样即使数据被泄露了,也只泄露了一部分,不法分子拿到这份数据也没啥用。14. 完整的接口文档 说实话,一份完整的API接口文档,在双方做接口对接时,可以减少很多沟通成本,让对方少走很多弯路。 接口文档中需要包含如下信息: 接口地址请求方式,比如:post或get请求参数和字段介绍返回值和字段介绍返回码和错误信息加密或签名示例完整的请求demo额外的说明,比如:开通ip白名单。接口文档中最好能够统一接口和字段名称的命名风格,比如都用驼峰标识命名。接口地址中可以加一个版本号v1,比如:v1/query/getCategory,这样以后接口有很大的变动,可以非常方便升级版本。统一字段的类型和长度,比如:id字段用Long类型,长度规定20。status字段用int类型,长度固定2等。统一时间格式字段,比如:time用String类型,格式为:yyyy-MM-dd HH:mm:ss。接口文档中写明AK/SK和域名,找某某单独提供等。
-
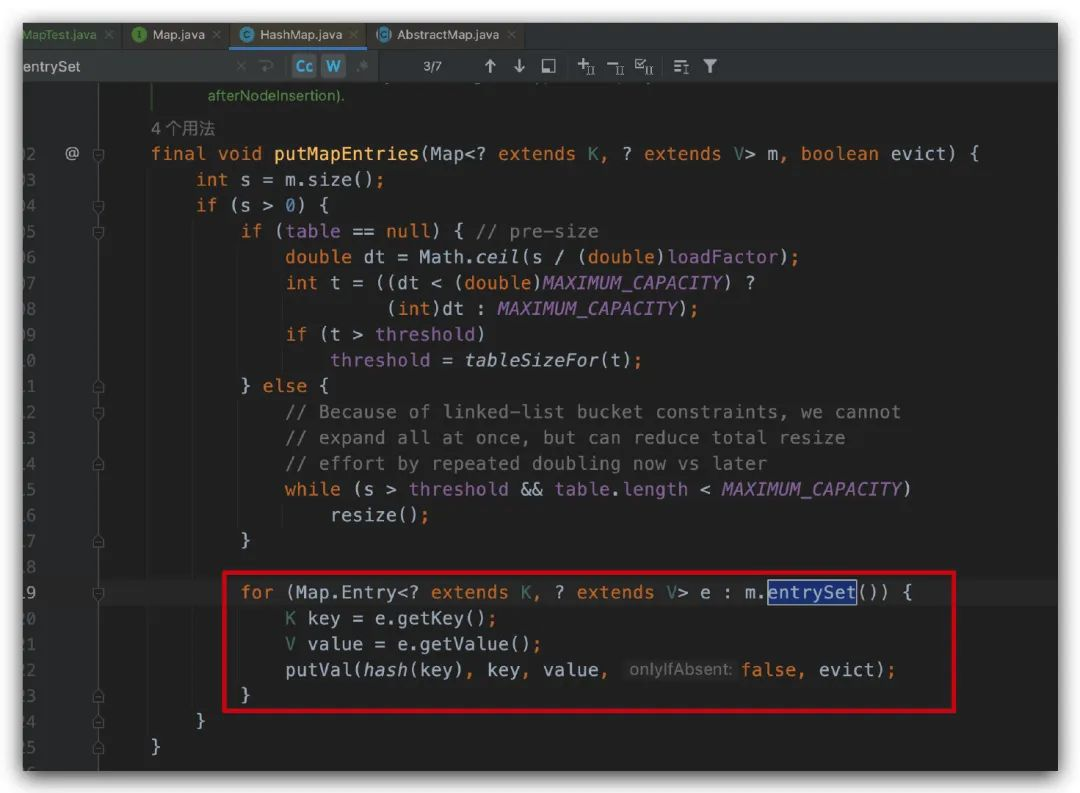
Java 中九种 Map 的遍历方式,你一般用的是哪种呢? {mtitle title="通过 entrySet 来遍历"/}1、通过 for 和 map.entrySet() 来遍历 第一种方式是采用 for 和 Map.Entry 的形式来遍历,通过遍历 map.entrySet() 获取每个 entry 的 key 和 value,代码如下。这种方式一般也是阿粉使用的比较多的一种方式,没有什么花里胡哨的用法,就是很朴素的获取 map 的 key 和 value。public static void testMap1(Map<Integer, Integer> map) { long sum = 0; for (Map.Entry<Integer, Integer> entry : map.entrySet()) { sum += entry.getKey() + entry.getValue(); } System.out.println(sum); }看过 HashMap 源码的同学应该会发现,这个遍历方式在源码中也有使用,如下图所示,putMapEntries 方法在我们调用 putAll 方法的时候会用到。2、通过 for, Iterator 和 map.entrySet() 来遍历 我们第一个方法是直接通过 for 和 entrySet() 来遍历的,这次我们使用 entrySet() 的迭代器来遍历,代码如下。public static void testMap2(Map<Integer, Integer> map) { long sum = 0; for (Iterator<Map.Entry<Integer, Integer>> entries = map.entrySet().iterator(); entries.hasNext(); ) { Map.Entry<Integer, Integer> entry = entries.next(); sum += entry.getKey() + entry.getValue(); } System.out.println(sum); }3、通过 while,Iterator 和 map.entrySet() 来遍历上面的迭代器是使用 for 来遍历,那我们自然可以想到还可以用 while 来进行遍历,所以代码如下所示。 public static void testMap3(Map<Integer, Integer> map) { Iterator<Map.Entry<Integer, Integer>> it = map.entrySet().iterator(); long sum = 0; while (it.hasNext()) { Map.Entry<Integer, Integer> entry = it.next(); sum += entry.getKey() + entry.getValue(); } System.out.println(sum); }这种方法跟上面的方法类似,只不过循环从 for 换成了 while,日常我们在开发的时候,很多场景都可以将 for 和 while 进行替换。2 和 3 都使用迭代器 Iterator,通过迭代器的 next(),方法来获取下一个对象,依次判断是否有 next。{mtitle title="通过 keySet 来遍历"/}上面的这三种方式虽然代码的写法不同,但是都是通过遍历 map.entrySet() 来获取结果的,殊途同归。接下来我们看另外的一组。4、通过 for 和 map.keySet() 来遍历前面的遍历是通过 map.entrySet() 来遍历,这里我们通过 map.keySet() 来遍历,顾名思义前者是保存 entry 的集合,后者是保存 key 的集合,遍历的代码如下,因为是 key 的集合,所以如果想要获取 key 对应的 value 的话,还需要通过 map.get(key) 来获取。public static void testMap4(Map<Integer, Integer> map) { long sum = 0; for (Integer key : map.keySet()) { sum += key + map.get(key); } System.out.println(sum); }5、通过 for,Iterator 和 map.keySet() 来遍历public static void testMap5(Map<Integer, Integer> map) { long sum = 0; for (Iterator<Integer> key = map.keySet().iterator(); key.hasNext(); ) { Integer k = key.next(); sum += k + map.get(k); } System.out.println(sum); }6、通过 while,Iterator 和 map.keySet() 来遍历public static void testMap6(Map<Integer, Integer> map) { Iterator<Integer> it = map.keySet().iterator(); long sum = 0; while (it.hasNext()) { Integer key = it.next(); sum += key + map.get(key); } System.out.println(sum); }我们可以看到这种方式相对于 map.entrySet() 方式,多了一步 get 的操作,这种场景比较适合我们只需要 key 的场景,如果也需要使用 value 的场景不建议使用 map.keySet() 来进行遍历,因为会多一步 map.get() 的操作。{mtitle title="Java 8 的遍历方式"/}注意下面的几个遍历方法都是是 JDK 1.8 引入的,如果使用的 JDK 版本不是 1.8 以及之后的版本的话,是不支持的。7、通过 map.forEach() 来遍历JDK 中的 forEach 方法,使用率也挺高的。public static void testMap7(Map<Integer, Integer> map) { final long[] sum = {0}; map.forEach((key, value) -> { sum[0] += key + value; }); System.out.println(sum[0]); }该方法被定义在 java.util.Map#forEach 中,并且是通过 default 关键字来标识的,如下图所示。这里提个问题,为什么要使用 default 来标识呢?欢迎把你的答案写在评论区。8、Stream 遍历public static void testMap8(Map<Integer, Integer> map) { long sum = map.entrySet().stream().mapToLong(e -> e.getKey() + e.getValue()).sum(); System.out.println(sum); }9、ParallelStream 遍历 public static void testMap9(Map<Integer, Integer> map) { long sum = map.entrySet().parallelStream().mapToLong(e -> e.getKey() + e.getValue()).sum(); System.out.println(sum); }这两种遍历方式都是 JDK 8 的 Stream 遍历方式,stream 是普通的遍历,parallelStream 是并行流遍历,在某些场景会提升性能,但是也不一定。测试代码上面的遍历方式有了,那么我们在日常开发中到底该使用哪一种呢?每一种的性能是怎么样的呢?为此阿粉这边通过下面的代码,我们来测试一下每种方式的执行时间。public static void main(String[] args) { int outSize = 1; int mapSize = 200; Map<Integer, Integer> map = new HashMap<>(mapSize); for (int i = 0; i < mapSize; i++) { map.put(i, i); } System.out.println("---------------start------------------"); long totalTime = 0; for (int size = outSize; size > 0; size--) { long startTime = System.currentTimeMillis(); testMap1(map); totalTime += System.currentTimeMillis() - startTime; } System.out.println("testMap1 avg time is :" + (totalTime / outSize)); // 省略其他方法,代码跟上面一致 }为了避免一些干扰,这里通过外层的 for 来进行多次计算,然后求平均值,当我们的参数分别是 outSize = 1,mapSize = 200 的时候,测试的结果如下当随着我们增大 mapSize 的时候,我们会发现,后面几个方法的性能是逐渐上升的。总结从上面的例子来看,当我们的集合数量很少的时候,基本上普通的遍历就可以搞定,不需要使用 JDK 8 的高级 API 来进行遍历,当我们的集合数量较大的时候,就可以考虑采用 JDK 8 的 forEach 或者 Stream 来进行遍历,这样的话效率更高。在普通的遍历方法中 entrySet() 的方法要比使用 keySet() 的方法好。
-
数据权限的设计思路 数据权限,主要进行数据的过滤,没相应的数据权限,则不能查询、操作相应的数据。数据权限实现方式如下:用户登录后,获取部门 ID 数据权限列表根据部门 ID 列表进行数据过滤,数据过滤表,都需要有部门 ID 字段一、自定义权限过滤注解@Target(ElementType.METHOD) @Retention(RetentionPolicy.RUNTIME) @Documented public @interface DataFilter { /** * 表的别名 */ String tableAlias() default ""; /** * 用户ID */ String userId() default "creator"; /** * 部门ID */ String deptId() default "dept_id"; }二、数据过滤,切面处理类@Aspect @Component public class DataFilterAspect { @Before("dataFilterCut(datafilter)") public void dataFilter(JoinPoint point,DataFilter datafilter) { Object params = point.getArgs()[0]; if(params != null && params instanceof Map){ UserDetail user = SecurityUser.getUser(); //如果是超级管理员或超级租户,则不进行数据过滤 if(user.getSuperAdmin() == SuperAdminEnum.YES.value() || user.getSuperTenant() == SuperTenantEnum.YES.value()) { return ; } try { //否则进行数据过滤 Map map = (Map)params; String sqlFilter = getSqlFilter(user, point); map.put(Constant.SQL_FILTER, new DataScope(sqlFilter)); }catch (Exception e){ } return ; } throw new RenException(ErrorCode.DATA_SCOPE_PARAMS_ERROR); } /** * 获取数据过滤的SQL */ private String getSqlFilter(UserDetail user, JoinPoint point) throws Exception { MethodSignature signature = (MethodSignature) point.getSignature(); Method method = point.getTarget().getClass().getDeclaredMethod(signature.getName(), signature.getParameterTypes()); DataFilter dataFilter = method.getAnnotation(DataFilter.class); //获取表的别名 String tableAlias = dataFilter.tableAlias(); if(StringUtils.isNotBlank(tableAlias)){ tableAlias += "."; } StringBuilder sqlFilter = new StringBuilder(); sqlFilter.append(" ("); //部门ID列表 List<Long> deptIdList = user.getDeptIdList(); if(CollUtil.isNotEmpty(deptIdList)){ sqlFilter.append(tableAlias).append(dataFilter.deptId()); sqlFilter.append(" in(").append(StringUtils.join(deptIdList, ",")).append(")"); } //查询本人数据 if(CollUtil.isNotEmpty(deptIdList)){ sqlFilter.append(" or "); } sqlFilter.append(tableAlias).append(dataFilter.userId()).append("=").append(user.getId()); sqlFilter.append(")"); return sqlFilter.toString(); } }三、数据过滤public class DataFilterInterceptor implements InnerInterceptor { @Override public void beforeQuery(Executor executor, MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, BoundSql boundSql) { DataScope scope = getDataScope(parameter); // 不进行数据过滤 if(scope == null || StrUtil.isBlank(scope.getSqlFilter())){ return; } // 拼接新SQL String buildSql = getSelect(boundSql.getSql(), scope); // 重写SQL PluginUtils.mpBoundSql(boundSql).sql(buildSql); } private DataScope getDataScope(Object parameter){ if (parameter == null){ return null; } // 判断参数里是否有DataScope对象 if (parameter instanceof Map) { Map<?, ?> parameterMap = (Map<?, ?>) parameter; for (Map.Entry entry : parameterMap.entrySet()) { if (entry.getValue() != null && entry.getValue() instanceof DataScope) { return (DataScope) entry.getValue(); } } } else if (parameter instanceof DataScope) { return (DataScope) parameter; } return null; } private String getSelect(String buildSql, DataScope scope){ try { Select select = (Select) CCJSqlParserUtil.parse(buildSql); PlainSelect plainSelect = (PlainSelect) select.getSelectBody(); Expression expression = plainSelect.getWhere(); if(expression == null){ plainSelect.setWhere(new StringValue(scope.getSqlFilter())); }else{ AndExpression andExpression = new AndExpression(expression, new StringValue(scope.getSqlFilter())); plainSelect.setWhere(andExpression); } return select.toString().replaceAll("'", ""); }catch (JSQLParserException e){ return buildSql; } } }四、配置类@Configuration public class DataScopeConfig { @Bean public InnerInterceptor dataFilterInterceptor() { return new DataFilterInterceptor(); } }
-
SpringCloud使用注解+AOP+MQ来实现日志管理模块 {mtitle title="简介"/}无论在什么系统中,日志管理模块都属于十分重要的部分,接下来会通过注解+AOP+MQ的方式实现一个简易的日志管理系统。{mtitle title="思路"/}注解: 标记需要记录日志的方法AOP: 通过AOP增强代码,利用后置/异常通知的方式获取相关日志信息,最后使用MQ将日志信息发送到专门处理日志的系统RabbitMQ: 利用解耦、异步的特性,协调完成各个微服务系统之间的通信1、日志表结构表结构(sys_log):CREATE TABLE `sys_log` ( `id` int(11) NOT NULL AUTO_INCREMENT COMMENT '唯一ID', `opt_id` int(11) DEFAULT NULL COMMENT '操作用户id', `opt_name` varchar(50) DEFAULT NULL COMMENT '操作用户名', `log_type` varchar(20) DEFAULT NULL COMMENT '日志类型', `log_message` varchar(255) DEFAULT NULL COMMENT '日志信息(具体方法名)', `create_time` datetime DEFAULT NULL COMMENT '创建时间', PRIMARY KEY (`id`) ) ENGINE=InnoDB AUTO_INCREMENT=17 DEFAULT CHARSET=utf8 COMMENT='系统日志表';实体类(SysLog):@Data public class SysLog { private static final long serialVersionUID = 1L; /** * 唯一ID */ @TableId(value = "id", type = IdType.AUTO) private Integer id; /** * 操作用户id */ private Integer optId; /** * 操作用户名 */ private String optName; /** * 日志类型 */ private String logType; /** * 日志信息(具体方法名) */ private String logMessage; /** * 创建时间 */ private Date createTime; }2、注解注解(SystemLog):仅作为标记的作用,目的让JVM可以识别,然后可以从中获取相关信息@Target: 定义注解作用的范围,这里是方法@Retention: 定义注解生命周期,这里是运行时@Target(ElementType.METHOD) @Retention(RetentionPolicy.RUNTIME) public @interface SystemLog { SystemLogEnum type(); }枚举(SystemLogEnum):限定日志类型范围public enum SystemLogEnum { SAVE_LOG("保存"), DELETE_LOG("删除"), REGISTER_LOG("注册"), LOGIN_LOG("登录"), LAUD_LOG("点赞"), COLLECT_LOG("收藏"), THROW_LOG("异常"), ; private String type; SystemLogEnum(String type) { this.type = type; } public String getType() { return type; } }3、AOP切面AOP(SysLogAspect):实现代码的增强,主要通过动态代理方式实现的代码增强。拦截注解,并获取拦截到的相关信息,封装成日志对象发送到MQ队列(生产端)@Component @Aspect @Slf4j public class SysLogAspect { @Autowired MqStream stream; //切点 @Pointcut("@annotation(cn.zdxh.commons.utils.SystemLog)") public void logPointcut(){} //后置通知 @After("logPointcut()") public void afterLog(JoinPoint joinPoint) { //一般日志 SysLog sysLog = wrapSysLog(joinPoint); log.info("Log值:"+sysLog); //发送mq消息 stream.logOutput().send(MessageBuilder.withPayload(sysLog).build()); } //异常通知 @AfterThrowing(value = "logPointcut()", throwing = "e") public void throwingLog(JoinPoint joinPoint, Exception e) { //异常日志 SysLog sysLog = wrapSysLog(joinPoint); sysLog.setLogType(SystemLogEnum.THROW_LOG.getType()); sysLog.setLogMessage(sysLog.getLogMessage()+"==="+e); log.info("异常Log值:"+sysLog); //发送mq消息 stream.logOutput().send(MessageBuilder.withPayload(sysLog).build()); } /** * 封装SysLog对象 * @param joinPoint * @return */ public SysLog wrapSysLog(JoinPoint joinPoint){ //获取请求响应对象 ServletRequestAttributes attributes = (ServletRequestAttributes) RequestContextHolder.getRequestAttributes(); HttpServletRequest request = attributes.getRequest(); MethodSignature signature = (MethodSignature)joinPoint.getSignature(); SysLog sysLog = new SysLog(); //获取方法全路径 String methodName = signature.getDeclaringTypeName()+"."+signature.getName(); //获取注解参数值 SystemLog systemLog = signature.getMethod().getAnnotation(SystemLog.class); //从header取出token String token = request.getHeader("token"); if (!StringUtils.isEmpty(token)) { //操作人信息 Integer userId = JwtUtils.getUserId(token); String username = JwtUtils.getUsername(token); sysLog.setOptId(userId); sysLog.setOptName(username); } if (!StringUtils.isEmpty(systemLog.type())){ sysLog.setLogType(systemLog.type().getType()); } sysLog.setLogMessage(methodName); sysLog.setCreateTime(new Date()); return sysLog; } }3、RabbitMQ消息队列MQ: 这里主要是通过Spring Cloud Stream集成的RabbitMQSpring Cloud Stream: 作为MQ的抽象层,已屏蔽各种MQ的各自名词,统称为input、output两大块。可以更方便灵活地切换各种MQ,如 kafka、RocketMQ等 (1)定义Input/Ouput接口(MqStream)@Component public interface MqStream { String LOG_INPUT = "log_input"; String LOG_OUTPUT = "log_output"; @Input(LOG_INPUT) SubscribableChannel logInput(); @Output(LOG_OUTPUT) MessageChannel logOutput(); }(2)MQ生产者注:这里使用到AOP切面的微服务,都属于MQ生产者服务引入依赖: 这里没有版本号的原因是spring cloud已经帮我们管理好各个版本号,已无需手动定义版本号<!--Spring Cloud Stream--> <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-stream</artifactId> </dependency> <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-stream-binder-rabbit</artifactId> </dependency>在程序入口开启MQ的Input/Output绑定:@SpringBootApplication(scanBasePackages = {"cn.zdxh.user","cn.zdxh.commons"}) @EnableEurekaClient @MapperScan("cn.zdxh.user.mapper") @EnableBinding(MqStream.class) //开启绑定 @EnableFeignClients public class YouquServiceProviderUserApplication { public static void main(String[] args) { SpringApplication.run(YouquServiceProviderUserApplication.class, args); } }yml配置: 在生产者端设置outputdestination: 相当于rabbitmq的exchangegroup: 相当于rabbitmq的queue,不过是和destination一起组合成的queue名binder: 需要绑定的MQ#Spring Cloud Stream相关配置 spring: cloud: stream: bindings: # exchange与queue绑定 log_output: # 日志生产者设置output destination: log.exchange content-type: application/json group: log.queue binder: youqu_rabbit #自定义名称 binders: youqu_rabbit: #自定义名称 type: rabbit environment: spring: rabbitmq: host: localhost port: 5672 username: guest password: 25802580注:完成以上操作,即完成MQ生产端的所有工作(3)MQ消费者 引入依赖、开启Input/Output绑定:均和生产者的设置一致yml配置:在生产者端设置inputspring: cloud: # Spring Cloud Stream 相关配置 stream: bindings: # exchange与queue绑定 log_input: # 日志消费者设置input destination: log.exchange content-type: application/json group: log.queue binder: youqu_rabbit binders: youqu_rabbit: type: rabbit environment: spring: rabbitmq: host: localhost port: 5672 username: guest password: 25802580消费者监听(LogMqListener): 监听生产者发过来的日志信息,将信息添加到数据库即可@Service @Slf4j public class LogMqListener { @Autowired SysLogService sysLogService; @StreamListener(MqStream.LOG_INPUT) public void input(SysLog sysLog) { log.info("开始记录日志========================"); sysLogService.save(sysLog); log.info("结束记录日志========================"); } }注:完成以上操作,即完成MQ消费端的所有工作4、应用 简述:只需将@SystemLog(type = SystemLogEnum.REGISTER_LOG),标记在需要记录的方法上,当有客户端访问该方法时,就可以自动完成日志的记录5、总结 流程:注解标记--->AOP拦截--->日志发送到MQ--->专门处理日志的系统监听MQ消息 --->日志插入到数据库